-
Video: Check if number is a palindrome in Python
So few months ago I posted this post about finding whether given number is a palindrome in Python using as little characters as possible. Out of the blue the team behind Webucator made great video basing on my blog post. To be honest I didn't anticipate such a thing and I'm very happy that it happened.
The video itself is excellent so I encourage you to watch it.
On their site you can find more videos. I believe it's also worth to mention that they offer pretty comprehensive Python classes.
-
Python: palindrome number test challenge
Recently, in one of the check.io missions i was playing with a task to find first palindromic prime number (palprime) greater than given argument. The challenge was to make code as small as possible. To check whether a number is a palprime we need to check whether it is both a prime and a palindromic number. In this post I'd like to focus on checking whether a number is palindromic.
Spoiler alert: think twice before reading this post if you're going to play the game. (source: http://40.media.tumblr.com/42ae198800aa76ad3c06878fd93a2d82/tumblr_nf8x7keJkF1rkt29io1_500.png)
(source: http://40.media.tumblr.com/42ae198800aa76ad3c06878fd93a2d82/tumblr_nf8x7keJkF1rkt29io1_500.png)
I believe most Python devs out there would quickly come with intuitive solution, presented below.str(n)==reversed(str(n))
The approach here is pretty straightforward - instead of doing arithmetics (like here) we can simply convert the number to a string and then compare it with reversed version of it. The solution consists of 24 characters. Can we make it smaller? (source: http://gemssty.com/wp-content/uploads/2013/03/cardboard_phone_2.jpg)
(source: http://gemssty.com/wp-content/uploads/2013/03/cardboard_phone_2.jpg)
It will be obvious to seasoned Python programmers to use fabulous Python slices, as shown below.str(n)==str(n)[::-1]
With this simple transformation we saved 4 characters - that's nice. How does it work? Python slices allow specifying start, stop, and step. If we omit start and stop and provide -1 as a step slicing will work in magical way: it will go through the sequence in right-to-left direction. As a side note I can add that slices in Python work in a little weird way - e.g. "abcd"[0:len("abcd"):-1] gives "" in result while "abcd"[len("abcd"):0:-1] renders "dcb". [::-1] specifying start and stop parameters would require us to append firs character to the result: "abcd"[len("abcd"):0:-1]+"a".
So, going back to the topic, are we stuck with this solution? If we can invert the logic (that won't be always the case), then there's other way that I discovered during trials. It required me to adapt rest of the code, but no single character was introduced. Instead, I saved one more.n-int(str(n)[::-1])
In essence, the idea is that if the number is palindromic then subtracting reversed version of it from the original version should result in 0. Here we are converting to string just to reverse the number and then there's back-to-integer conversion.
So I ended up with 19 characters thinking about what else I can do. I literally ran out of ideas, so I though of googling for operators available in Python language. During my life I managed to ensure myself that even if you think you have mastered your language of choice, you are wrong (C++ helped me to shape this attitude with stuff like template unions, secret shared_ptr c-tors etc. ;)).
In the haystack of results I found a needle. It turns out that in Python 2.x there's a possibility to convert a number (even if it's held in a variable) to a string using backticks (a.k.a backquotes, reverse quotes). Well... what can I say. I never expected existence of such thing, especially in Python.
Fortunately it does the job, so was able to use this feature and cut down length of the test to 14. Awesome!`n`==`n`[::-1]Above solution is the shortest I was able to come with. I wouldn't be surprised if there were shorter ones, though. If you know how to make it shorter, please let me know in comments.
Besides making this check so short I was curious what are differences between conversions and reversions in terms of performance. I decided to give it a go on my machine (i5-3320M 2.6GHz).
python -m timeit 'n=2**30; str(n)'
python -m timeit 'n=2**30; repr(n)'
python -m timeit 'n=2**30; `n`'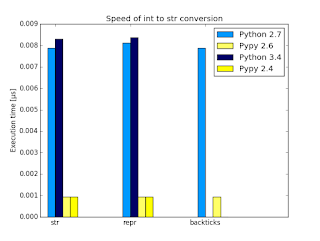
python -m timeit 's=qwertyuiopasfghjklzxcvbnm; rs=''.join(reversed(s))'
python -m timeit 's=qwertyuiopasfghjklzxcvbnm; rs=s[::-1]'My conclusions are:
- there's very slight (almost unnoticeable) difference between three methods of converting integer to string
- for some reason Python3.4 is slower than Python2.7
- Pypy cruelly outperforms Python, as usual. If you care about performance you should use pypy.
- there's almost no difference between reverse(n) and [::-1] when it comes to speed
The fact that there are no performance differences between reverse() and [::-1] surprised me a bit. By looking into byte code I can only assume that in my particular case different set of operations yielded the same performance results.reversed [::-1]
-------------------------------------------------------------------
0 LOAD_CONST 0 ('qwer...') 0 LOAD_CONST 0 ('qwer...')3 STORE_NAME 0 (s) 3 STORE_NAME 0 (s)6 LOAD_CONST 1 ('') 6 LOAD_NAME 0 (s)9 LOAD_ATTR 1 (join) 9 LOAD_CONST 1 (None)12 LOAD_NAME 2 (reversed) 12 LOAD_CONST 1 (None)15 LOAD_NAME 0 (s) 15 LOAD_CONST 3 (-1)18 CALL_FUNCTION 1 (1 pos, 0 kw) 18 BUILD_SLICE 321 CALL_FUNCTION 1 (1 pos, 0 kw) 21 BINARY_SUBSCR24 STORE_NAME 3 (rs) 22 STORE_NAME 1 (rs)27 LOAD_CONST 2 (None) 25 LOAD_CONST 1 (None)30 RETURN_VALUE 28 RETURN_VALUEIn case of conversion from integer to a string I anticipated that str and repr will yield similar results. What I didn't know was how backticks will perform. By looking into byte code I can say that the only difference is that backticks don't call any function, but use UNARY_CONVERT op directly.
str ``
----------------------------------------------------------------------------
0 LOAD_CONST 0 (1234567890) 0 LOAD_CONST 0 (1234567890)
3 STORE_NAME 0 (n) 3 STORE_NAME 0 (n)
6 LOAD_NAME 1 (str) 6 LOAD_NAME 0 (n)
9 LOAD_NAME 0 (n) 9 UNARY_CONVERT
12 CALL_FUNCTION 1 10 STORE_NAME 1 (s)
15 STORE_NAME 2 (s) 13 LOAD_CONST 1 (None)
18 LOAD_CONST 1 (None) 16 RETURN_VALUE
21 RETURN_VALUE -
CheckIo.org - A game for software engineers :)

I've just found an excellent way of spending an evening as a programmer - playing a game designed for software engineers :)
Since I discovered that site by an accident I think it is worth to mention it here so maybe you will also get interested. In the game you, in essence, solve various tasks to enable more "levels".
The only one drawback I can see is that only Python is supported (I'm Python enthusiast, but I know a lot of people that are more into Go, JavaScript etc.).
To give you a quick grasp without spoilers let me post here my solution for the very first (and very basic) task - FizzBuzz. This is the simplest one and can be quickly implemented, but I'm kind of a person that like to over-engineer.return ''.join([['Fizz ', ''][(n%3)!=0], ['Buzz', ''][(n%5)!=0]]).strip() or str(n)
You think this is weird? Check out solution from nickie :)return ("Fizz "*(1-n%3)+"Buzz "*(1-n%5))[:-1]or str(n)
Happy hacking!! -
KnowCamp Wrocław / More functional C++14
-
Real Boost.multi_index performance

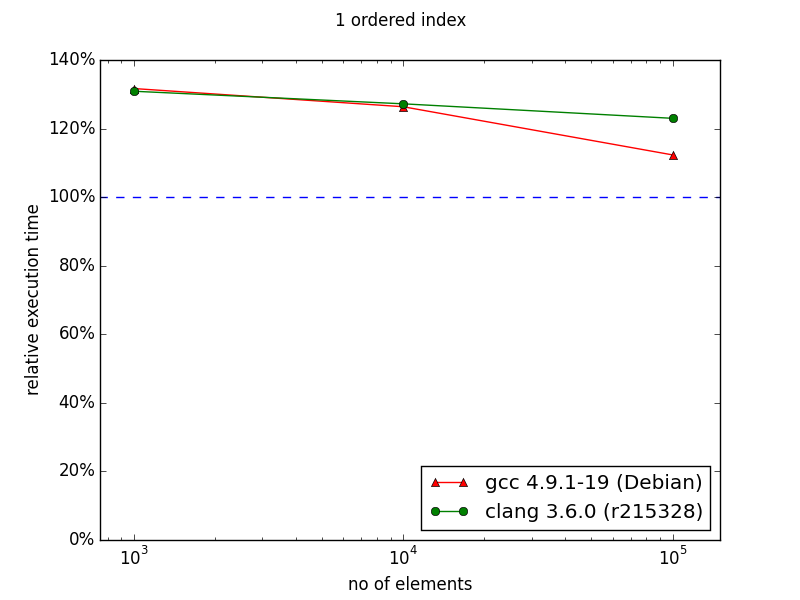
Update 09.05.2015: thanks to Joaquín it turned out that I had slight bug in my plotting script - x tick labels were wrong. All pictures have been fixed.
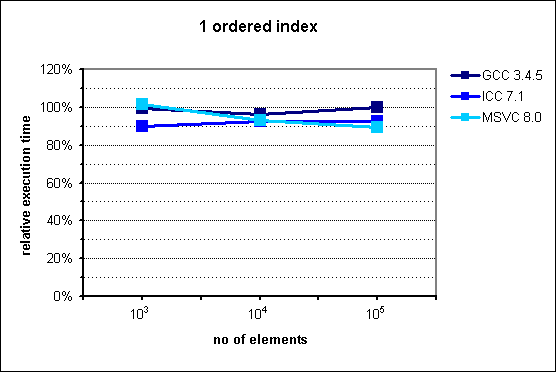
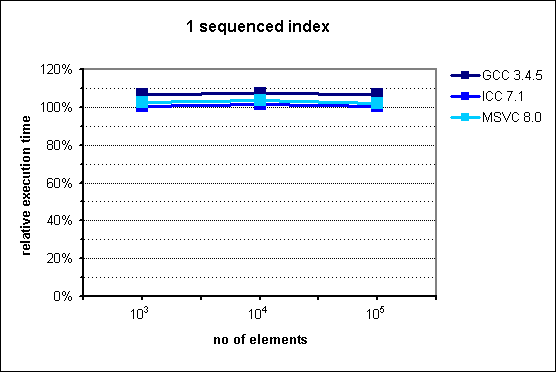
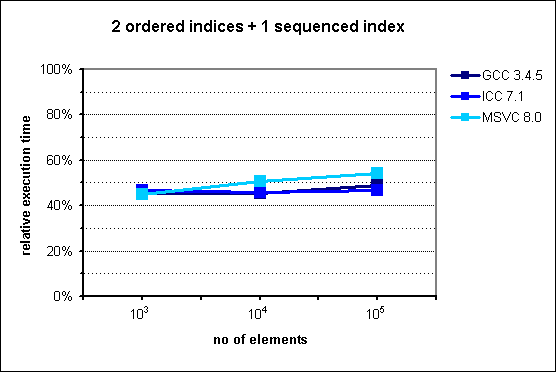
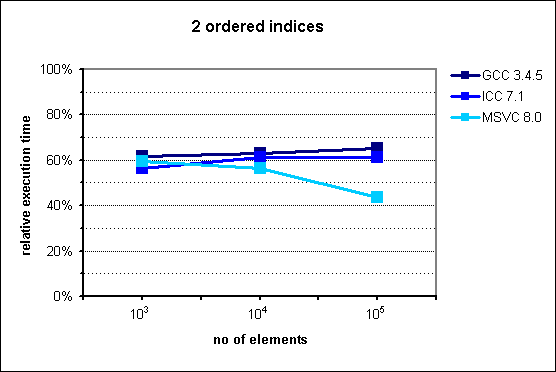
Several months ago I prepared and conducted a presentation about multi_index library from Boost at Nokia TechMeetUp. Essentially I showed that it is pretty useful library that should be used when there's a need to represent the same data with multiple "views". For instance, if we have to access the same list of something sorted by different attributes, Boost.MultiIndex seems to be very good choice as the documentation claims strong consistency and, what's also important, better performance. What's also interesting is that Facebook's library - folly - utilizes that in its TimeoutQueue class.In the middle of the presentation I put some performance graphs which I mindlessly copied them from the documentation. Had I known that they are old, I'd never do that. Fortunately it was pointed out by friend of mine. These graphs in fact illustrate performance gains, but measurements were made with ancient compiler versions like GCC 3.4.5.After the presentation I promised myself that I'll investigate this a bit, but as usual time didn't permit. Till now.I made measurements with newer versions of GCC and Clang. Unfortunately I have no access to Visual Studio. If you can provide me VS stats I'd be pleased, though.Here are my results for:CPU: i5-3320MRAM: 8GBOS: Debian 7Compilation flags: -O3Boost version: 1.57Images from documentation are placed at the right side.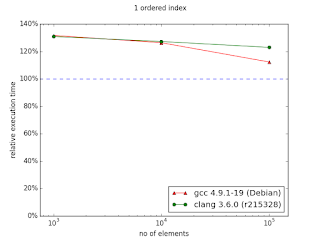
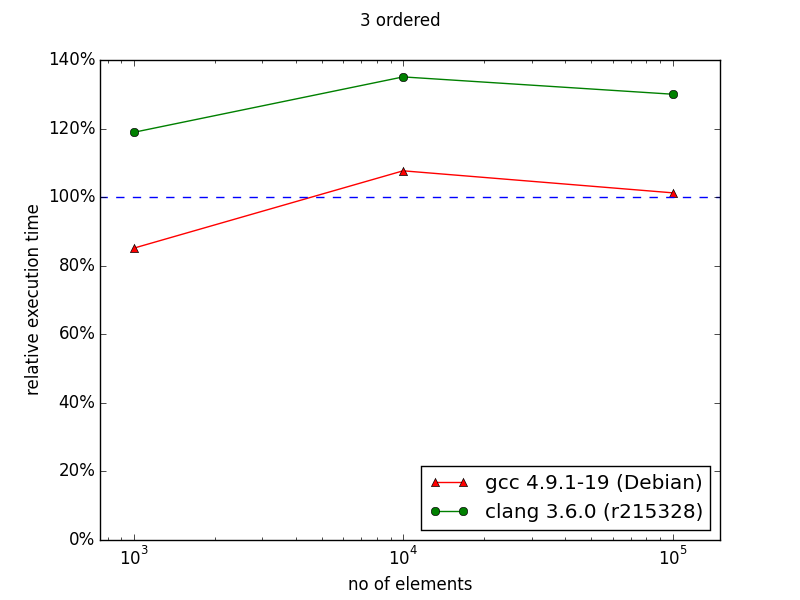
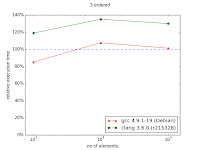
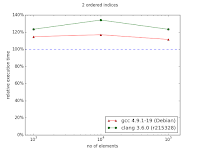
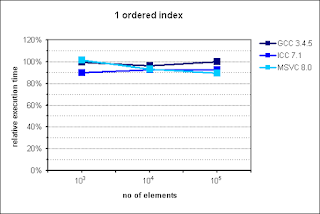 In the case of ordered index it's visible that either standard containers were improved or compilers learned how to optimize code using them better. Nevertheless, there is visible trend showing that with more than 106 entries, multi_index container could perform better than naive approach.
In the case of ordered index it's visible that either standard containers were improved or compilers learned how to optimize code using them better. Nevertheless, there is visible trend showing that with more than 106 entries, multi_index container could perform better than naive approach.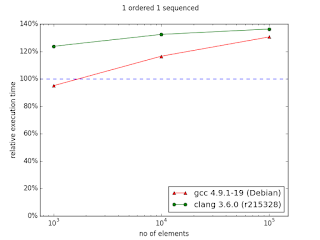
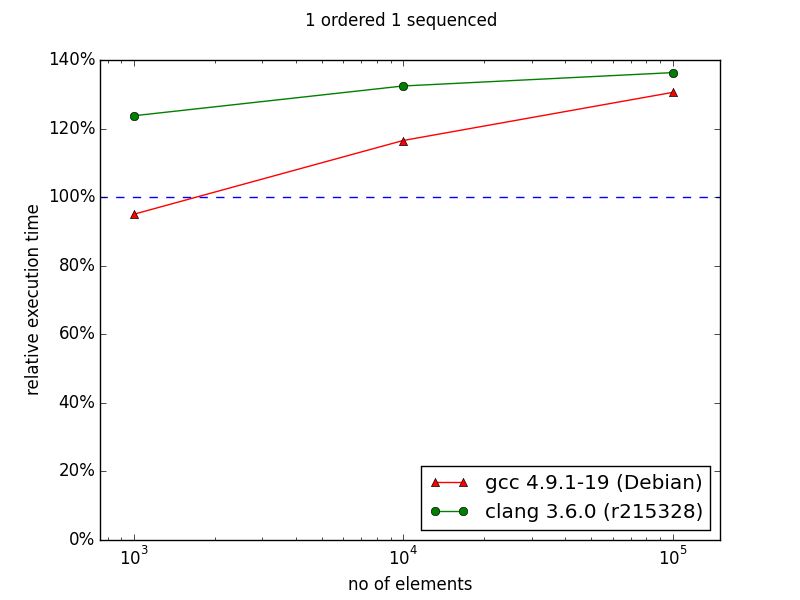
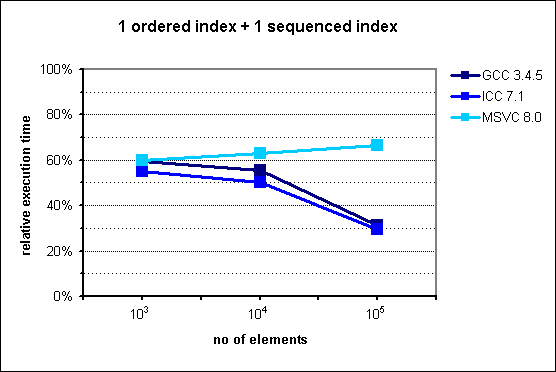
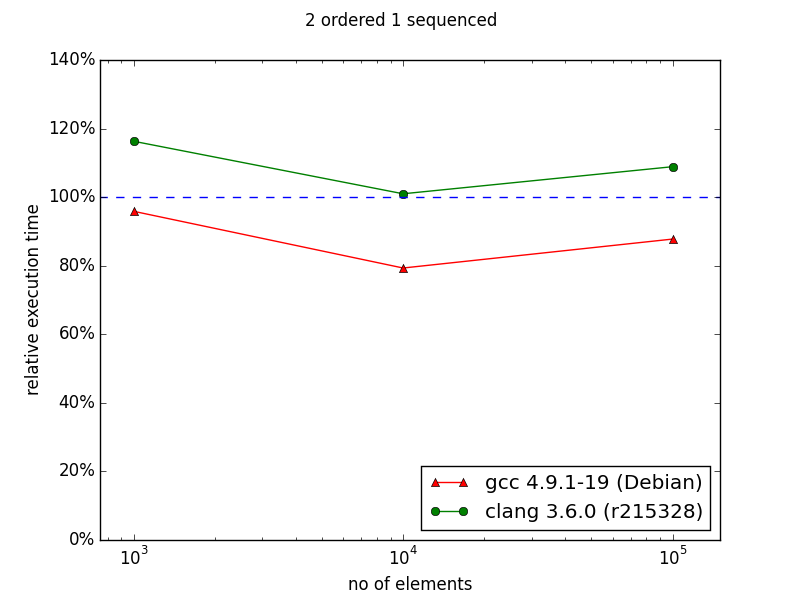
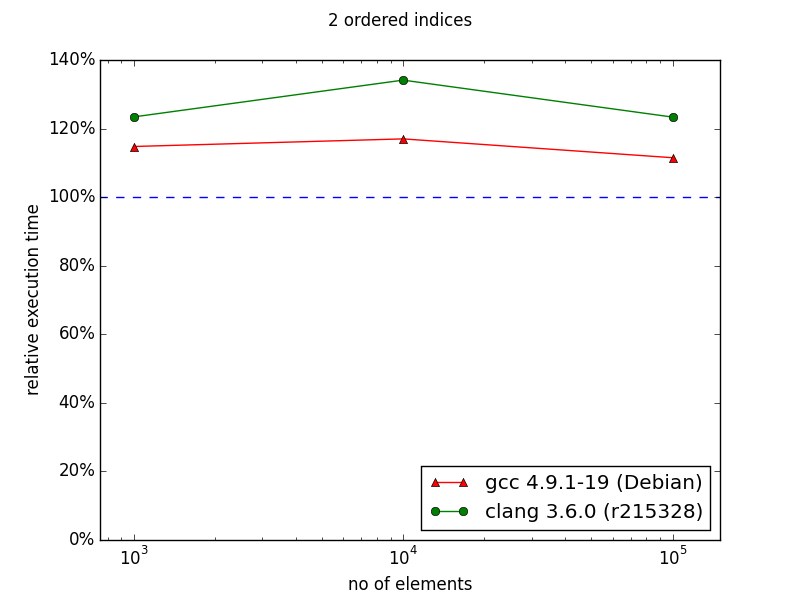
 In case of two indexes - one indexed and the second sequenced situation changes. In the original chart from the documentation we can observe huge improvement in favor to multi_index starting from 105 elements. My results are quite different - there is no performance gain with multi_index. For 106 elements the difference is dramatic comparing the two diagrams: ~130% and ~30%.
In case of two indexes - one indexed and the second sequenced situation changes. In the original chart from the documentation we can observe huge improvement in favor to multi_index starting from 105 elements. My results are quite different - there is no performance gain with multi_index. For 106 elements the difference is dramatic comparing the two diagrams: ~130% and ~30%.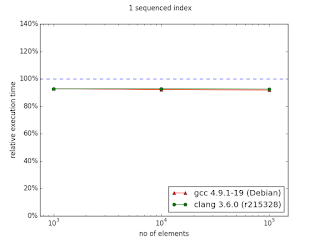
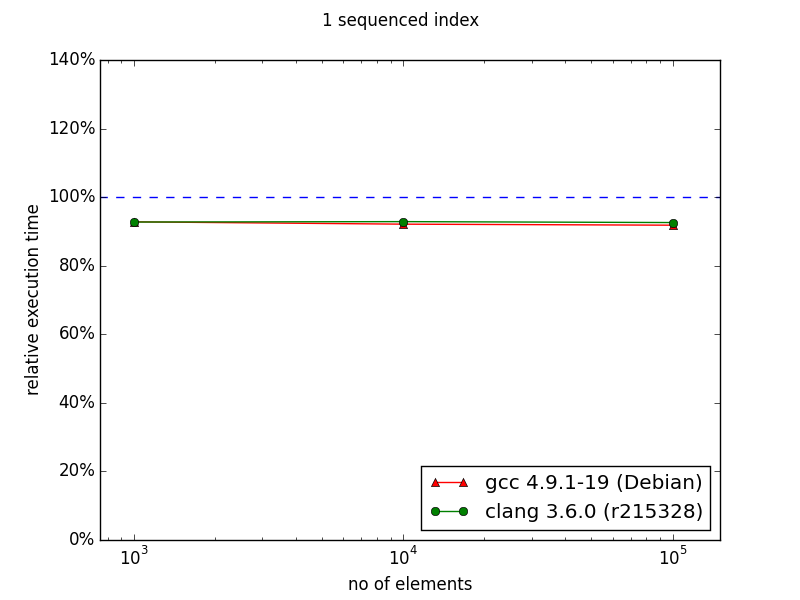
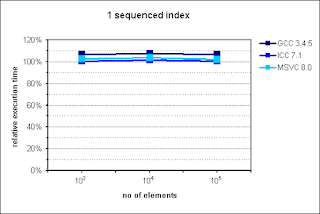 Interestingly, on my machine multi_index performed better in case of only 1 sequenced index. This is surprise for me, because in the documentation it is opposite. Well, in this scenario multi_index outperformed naive approach.
Interestingly, on my machine multi_index performed better in case of only 1 sequenced index. This is surprise for me, because in the documentation it is opposite. Well, in this scenario multi_index outperformed naive approach.
Rest of diagrams are presented below. As you can see they illustrate that multi_index documentation is outdated. Sometimes there are some performance gains, but not that huge as presented in diagrams from documentation.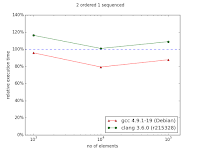
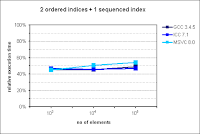


Unfortunately currently I have no time to dig in into this. (Maybe in next days I'll have some time to check how cache-friendly multi_index library is). Nevertheless, everything that I showed pushes me even harder into opinion that everything should be measured - even 3rd-party things with a lot of promises in the documentation.
-
Software engineers - the new working class
Is software engineering a prestige occupation? Do programmers have any special abilities that are not possessed by the rest of society? Are there any particular predispositions that make someone a good programmer?These, among others, questions appeared in my mind during another-in-the-row conversation about nothing with friend of mine. In this post I share my reflections about this topic by putting software engineers in pretty different segment of labor - proletariat (also referred as: working class, blue-collar workers).
Programmers and programmers
Just to make it clear - generally speaking I'm far for generalizing. I just hope that you agree with me that there are a lot sorts of programmers. On the one pole we have very creative and intelligent individuals while the other pole is a place filled with so-called code monkeys. However, there are exceptions. I'm not going to go into details with that. I'm going to focus more on how market demand affected occupation itself rather than saying who is who.
Blue-collar developers
Blue-collar software workers, in my opinion, are (or will soon be) the majority in computer software world. I anticipate that Pareto's rule would work here (80%/20%), but it's extremely hard to prove so I left it as a guess. But who are traditional blue-collar workers in a first place? In order not to make mistake in reasoning, let me stick to the Wiki definition of the proletariat.
The proletariat (/ˌproʊlɪˈtɛəriːət/ from Latin proletarius) is a term used to describe the class of wage-earners (especially industrial workers) in a capitalist society whose only possession of significant material value is their labour-power (their ability to work);[1] a member of such a class is a proletarian.
What does it say to us? Well, certainly one point is clear - the thing that blue-collar worker can offer to her employee is her labor power. Undoubtedly it was the case with industrial workers in the very beginning of the 20th century. It also applies to nowadays jobs, but programmers?
What an average programmer does?
One can simply say that a programmer writes computer software. Of course it's true, but I'd rather say that programmer thinks a lot. Primarily about solving problems. From this sentence it almost spills out that programmers must be very intelligent and knowledgeable creatures. Solving problems require strong analytic skills, doesn't it? This isn't necessarily the truth.
Problems and problems
There are big problems and small problems. Usually big problems are solved by highly intelligent persons with strong education background. This is because, for example, you won't sort 10TB of data with bubble sort algorithm, will you? And efficient sorting know-how is not ubiquitous knowledge. Also, such problems require that the solution smoothly scales. On the other hand majority of programmers deal with small problems involving small problem sets, because they can cope with them. In other words, regardless how stupid it would be, sorting 1kB of data with bubble sort won't hurt. More importantly this problem set will never grow. In such cases our blue-collar programmers feel like ducks in the water.
And perhaps there's nothing wrong with that, but it has interesting implication.
"Make it work"
It is often a good approach to make programs work, then make them work correctly, and eventually improve them so they are fast. The last step can be omitted, though. I believe that this is what we are facing nowadays. Only small part of programmers must care about performance - and it is likely that they are library writers.
So in "user code" it usually doesn't matter who and how will implement some functionality. It doesn't matter what kind of algorithm is under the bonnet. For almost all the time it will be fine.
That leads us to the following question. What such a programmer really needs to know in order to write software?
if, for, class, import
In my humble opinion the basic set of needed tools are: if for conditions, for for looping, class for representing relations, and import for including someone's else work into our project. Of course you should also know what are functions and variables and how to use them.
If you're not low-level programmer you won't need to know anything about operating system, memory management, and so on. Perhaps I missed some other useful knowledge, but this is the basic toolbox.
As you can see it's not that complicated. Thanks to that it is possible for a lot of people to write software. And... if you were conscious in the school you know that the more mass the more gravity force. Being a programmer is not exclusive anymore. This occupation becomes like all other occupations - just ordinary. It doesn't mean that there are no extraordinary people within programmers community, but it shows that programmers are becoming new working class. The only one thing that they offer is usually some kind of labor-power - like the Proletariat.
Number of programmers in the world is continuously increasing. Actually I don't believe we will see any decline in this area in next few years. In Britain the government even introduced programming course in a primary school! It's likely that in next years everyone will be a programmer - like everyone can read.
SDD - StackOverflow driven development
Things are getting even more funny when we think about the internet. Mainly StackOverflow and Google. Believe it or not, but how hard is to program something if you can simply ask Google a question and read an answer on StackOverflow? The other time you will find a blog post saying what to do in detailed steps. You don't even need to know all this stuff. All that is required is that you know how to use search engine and master Ctrl-C-then-Ctrl-V combination.
This topic is deeper. There are many other aspects that could be covered, but it would make this post too long. So... I leave you with these disturbing thoughts :) -
type_traits: GCC vs Clang
Recently I was writing another article for polish developer journal "Programista" (eng. Programmer). This time I decided to focus on type_traits library - what can we find inside, how it is implemented, and finally - what can we expect in the future (mainly in terms of compile-time reflection).
While writing I was not referring to any particular implementation, but Clang and GCC implementations were opened on the second monitor all the times. I noticed some differences that I'd like to document here.
First things first. Whole post is based on:- GCC (libstdc++v3): c6292d1d5dc2c42aaaa2731ea8721dbe4b6fcb6f
- Clang (libcxx): 216318
100 template<typename...>
101 struct __or_;
102
103 template<>
104 struct __or_<>
105 : public false_type
106 { };
107
108 template<typename _B1>
109 struct __or_<_B1>
110 : public _B1
111 { };
They are used in following fashion:709 /// is_unsigned
710 template<typename _Tp>
711 struct is_unsigned
712 : public __and_<is_arithmetic<_Tp>, __not_<is_signed<_Tp>>>::type
713 { };
At first glance everything looks nice. However you won't find such things in Clang's type_traits implementation. Clang approach is to use standard template mechanisms, like template specialization:688 // is_unsigned
689
690 template <class _Tp, bool = is_integral<_Tp>::value>
691 struct __libcpp_is_unsigned_impl : public integral_constant<bool, _Tp(0) < _Tp(-1)> {};
692
693 template <class _Tp>
694 struct __libcpp_is_unsigned_impl<_Tp, false> : public false_type {}; // floating point
695
696 template <class _Tp, bool = is_arithmetic<_Tp>::value>
697 struct __libcpp_is_unsigned : public __libcpp_is_unsigned_impl<_Tp> {};
698
699 template <class _Tp> struct __libcpp_is_unsigned<_Tp, false> : public false_type {};
700
701 template <class _Tp> struct _LIBCPP_TYPE_VIS_ONLY is_unsigned : public __libcpp_is_unsigned<_Tp> {};
There's no doubt - GCC's version is more human-friendly. We can read it like it was a book and everything is clear. Reading Clang version is much more harder. Code is bloated with template stuff and there is a lot of kinky helpers.
On the other hand Clang developers use things that are shipped with the C++ compiler. Therefore, at least in theory, compilation should take less time for Clang implementation. It's not that easy to test this, but there's fancy new tool out there - templight. It is a tool that allows us to debug and profile template instances ;)
After some time playing with templight I got following results for simple program that just includes type_traits library, but in two versions: GCC and Clang.GCC Clang Template instantiations* 3 5 Template memoizations* 59 45 Maximum memory usage ~957kB ~2332kB
When we sum instantiations and memoizations it turns out that assumption was right - Clang implementation of type_traits library should be slightly faster. But of course it depends on how compilers are implemented.
Another interesting fact is that during compilation of Clang's type_traits a lot more memory is consumed (comparing to GCC's version).
Both versions of type_traits were compiled using Clang 3.6 (SVN) with templight plugin, so there's no data related to GCC. It may be that for GCC GCC's version of type_traits is better.
The second thing that I've noticed is that Clang's type_traits strive to not rely on compiler built-ins as much as possible while GCC does. Good example here are implementations for std::is_class and std::is_enum.
GCC approach here is to simply use compiler built-ins, like __is_class and __is_enum.411 /// is_class
...
412 template<typename _Tp>
413 struct is_class
414 : public integral_constant<bool, __is_class(_Tp)>
415 { };399 /// is_enum
400 template<typename _Tp>
401 struct is_enum
402 : public integral_constant<bool, __is_enum(_Tp)>
403 { };487 { "__is_class", RID_IS_CLASS, D_CXXONLY },
489 { "__is_enum", RID_IS_ENUM, D_CXXONLY },
Clang, on contrary, utilizes metaprogramming tricks developed by the community. In case of std::is_class implementation is based on function overloading - the first version of function __is_class_imp::__test accepts pointer to a member and thus will be chosen by the compiler only if the type is a class or union. Therefore second check is needed as well. Simple and brilliant.413 namespace __is_class_imp
414 {
415 template <class _Tp> char __test(int _Tp::*);
416 template <class _Tp> __two __test(...);
417 }
418
419 template <class _Tp> struct _LIBCPP_TYPE_VIS_ONLY is_class
420 : public integral_constant<bool, sizeof(__is_class_imp::__test<_Tp>(0)) == 1 && !is_union<_Tp>::value> {};
In case of enums there's also interesting bit in Clang implementation:500 template <class _Tp> struct _LIBCPP_TYPE_VIS_ONLY is_enum
501 : public integral_constant<bool, !is_void<_Tp>::value &&
502 !is_integral<_Tp>::value &&
503 !is_floating_point<_Tp>::value &&
504 !is_array<_Tp>::value &&
505 !is_pointer<_Tp>::value &&
506 !is_reference<_Tp>::value &&
507 !is_member_pointer<_Tp>::value &&
508 !is_union<_Tp>::value &&
509 !is_class<_Tp>::value &&
510 !is_function<_Tp>::value > {};
Voila! No built-ins needed ;)
The last thing I'd like to mention here is std::is_function. GCC's approach here is a bit ridiculous, because it needs a lot of specializations (there are 24 of them so I don't want to include 'em all).490 template<typename _Res, typename... _ArgTypes>
491 struct is_function<_Res(_ArgTypes......) volatile &&>
492 : public true_type { };
493
494 template<typename _Res, typename... _ArgTypes>
495 struct is_function<_Res(_ArgTypes...) const volatile>
496 : public true_type { };
497
498 template<typename _Res, typename... _ArgTypes>
499 struct is_function<_Res(_ArgTypes...) const volatile &>
500 : public true_type { };
501
502 template<typename _Res, typename... _ArgTypes>
503 struct is_function<_Res(_ArgTypes...) const volatile &&>
504 : public true_type { };
I think that this double template unpacking (or nested unpacking - I don't know how to name this) is good example how to make implementation look like a nightmare. When you have hammer in your hand everything is looking like a nail, isn't it ;)?
* Memoization - "Memoization means we are _not_ instantiating a template because it is already instantiated (but we entered a context where wewould have had to if it was not already instantiated)." -
C++14 template variables in action
As some of you know, in November I conducted a presentation "Metaprogramming in C++: from 70's to C++17" at Code::Dive conference. One of things that I mentioned about C++ templates was what actually can be a template. One of the things that I covered was template variables from C++14. In this post I'd like to present them in action.
However, before I move forward I'd like to see if you can spot the mistake I made during the presentation. I said that following things can be templated in C++. Can you point out the mistake?- C++98: class, structure, (member) function
- C++11: using directive
- C++14: variable
The question is tricky. It turns out that since C++98 it was possible to make template union as well. I don't know how about you, but I haven't use union for more than five years from now. I saw it recently as a storage for optional class, though. It's a rare thing, but definitely worth knowing.
Okay, enough off-topic. Let's get back to template variables from C++14. This feature was introduced with N3651 proposal. The proposal argues that in C++ we should have legal mechanisms instead of workarounds like static const variable defined in a class, or value returned from constexpr function.
But what are the use cases of this? The proposal gives us example use case presented below.1 template <typename T>
2 constexpr T pi = T(3.1415926535897932385);
3
4 template <typename T>
5 T area_of_circle_with_radius(T r) {
6 return pi<T> * r * r;
7 }
Although this is complete example it was quite hard for me to figure out other use cases in two shakes. The breakthrough came with this commit to Clang's libcxx library. It used this very new feature to make simpler versions of type_traits templates. I hope that following listing is illustrating this well.1 namespace ex = std::experimental;
2
3 // ...
4 {
5 typedef void T;
6 static_assert(ex::is_void_v<T>, "");
7 static_assert(std::is_same<decltype(ex::is_void_v<T>), const bool>::value, "");
8 static_assert(ex::is_void_v<T> == std::is_void<T>::value, "");
9 }
10 {
11 typedef int T;
12 static_assert(!ex::is_void_v<T>, "");
13 static_assert(ex::is_void_v<T> == std::is_void<T>::value, "");
14 }
15 {
16 typedef decltype(nullptr) T;
17 static_assert(ex::is_null_pointer_v<T>, "");
18 static_assert(std::is_same<decltype(ex::is_null_pointer_v<T>), const bool>::value, "");
19 static_assert(ex::is_null_pointer_v<T> == std::is_null_pointer<T>::value, "");
20 }
21 // ...
So from this commit onward we are able to write more concise and more readable code in one shot. This nice addition to C++ is practical not only for template variables, but also for making things easier. -
Angular.js + CORS + IE11 + invalid URL = "SCRIPT7002: XMLHttpRequest: Network Error 0x7b..."
This time something completely different. I just hope that in future this post might save 2 hours of debugging.
In Nokia I'm the creator of internal search engine (but I actually do this in my leisure time). Something like Google, but only for our intranet. As you may expect it would be an overkill to employ C++ in front-end. Therefore I used Angular.js to do the job. And it does it's job pretty well.
However, recently one user came to me with a complain that he cannot log in into the site. I requested a log from console and got following.
SCRIPT7002: XMLHttpRequest: Network Error 0x7b, The filename, directory name, or volume label syntax is incorrect.
File: *************
Error: Unable to connect to the target server.
at Anonymous function (https://******/bower_components/angular/angular.min.js:80:237)
at t (https://******/bower_components/angular/angular.min.js:76:22)
at Anonymous function (https://******/bower_components/angular/angular.min.js:73:367)
at J (https://******/bower_components/angular/angular.min.js:100:404)
[...]
At first glance I thought that this is some kind of bug in IE11 related to missing Origin header in XHR requests (this header is needed if you use CORS (Cross-Origin Resource Sharing)). During debugging this it turned out that the problem is completely different. And quite kinky one.
In some front-end configuration I used following URL.
https:///******
Note that there are three forward slashes. Do you think that IE11 can handle that?
Apparently no. The worst thing is that this part of URL was not present in JavaScript console in the browser.
Removing one forward slash fixed the bug, but 2 hours were wasted anyway. -
TypeId using constexpr objects
Today we had another interesting conversation at the office. It all started with me explaining to my colleague what static keyword does in respect to free functions. At that time I was wondering whether the same rules apply to variables defined in the scope of translation unit. And... no surprise (luckily not today). However the conversation evolved... and I ended up trying to implement my own compile-time TypeId functionality with no memory footprint (one that vanishes from binary). Please don't ask me how we jumped from static keyword to TypeId ;) It just happened and I'd like to share some thoughts about it with you.
TypeId? Wait.. what exactly is it?
With moderate Google-fu (or having this knowledge before) it takes less than minute to find out typeid operator which is available since C++98. It returns std::type_info which contains some information about type provided as an argument. It is worth noticing that returned value is a lvalue and it lives till the end of your application. What does it mean? Yes, you're right. It all happens in run-time. Since this is not what I wanted to have, this solution was unacceptable.
Even if it would be acceptable - this type information is not available if you don't compile your program with RTTI (Run Time Type Information, -frtti switch for Clang/GCC). It means that there's performance penalty. We have to pay for it, but we'd rather like not to. What do we do, then?
Black magic applied
To solve this problem in compile-time we have to somehow map distinct types to some unique identifiers. I believe there are a lot of approaches over there, but my favorite one is to employ function addresses. Why function addresses? Because every two distinct functions are guaranteed to have different (unique) addresses. In other words two functions can't share one address in memory. Compiler must do this that way, for sure.
However, how can we make use of this fact to create identifier↔type mapping? It's easy - we'll treat addresses of static member functions from class templates as our identifiers. Following snippet illustrates this idea.1 using TypeId = uintptr_t;
2
3 template <typename T>
4 struct TypeIdGenerator {
5 static TypeId GetTypeId() {
6 return reinterpret_cast<uintptr_t>(&GetTypeId);
7 }
8 };
So now you may be asking yourself a question about this weird uintptr_t type. Why this particular type? Why not simply integer? It is all because size of a pointer (in this scenario pointer to method) can be of bigger size than other types like int or long. Actually C++ standard does not say a word about size of embedded types, but this is topic for other blog post ;-). The size of unitptr_t is guaranteed to be the same as size of pointers - and that saves us a day.
There's also one more caveat here, though. Unlike POSIX, C++ standard does not support casting pointers to functions to other pointers or scalar types. It is because code may (theoretically) be located in different kind of memory (with different size of words etc.) than data. That is the main reason why I was forced to use reinterpret_cast in above example.
Back to functions
Okay, but still there is one problem with presented code snippet. It leaves trace in assembly (and thus also in binary file):1 # g++-4.9.1, -std=c++14 -Os
2 .LHOTB0:
3 # TypeIdGenerator<int>::GetTypeId()
4 .weak _ZN15TypeIdGeneratorIiE9GetTypeIdEv
5 .type _ZN15TypeIdGeneratorIiE9GetTypeIdEv, @function
6 _ZN15TypeIdGeneratorIiE9GetTypeIdEv:
7 .LFB2:
8 .cfi_startproc
9 movl $_ZN15TypeIdGeneratorIiE9GetTypeIdEv, %eax
10 ret
11 .cfi_endproc
To overcome this I tried to use constexpr functions from C++11. I thought it is a good direction because these functions can be both compile-time and run-time. So maybe compile-time version will have some kind of compile-time address that we can use? And maybe this address will not be present in run-time binary? Let's see.1 using TypeId = uintptr_t;
2
3 template <typename T>
4 constexpr inline void GetTypeId() {}
Now we can get address of this free function, but unfortunately it still has to have some room in memory. So I was very wrong. However, we already limited implementation of this function to single ret instruction. At least that ;-).1 _Z9GetTypeIdIiEvv:
2 .LFB2:
3 .cfi_startproc
4 ret
5 .cfi_endproc
Mission failed. I'm sorry. Maybe you have some other ideas how to achieve what I want? Nevertheless I decided to check one last thing - constexpr objects.
Constexpr objects
This was my last resort, but I knew it's not gonna work...1 using TypeId = uintptr_t;
2
3 template <typename Type>
4 struct GetTypeId {
5 constexpr GetTypeId() {};
6 };
7
8 int main(void) {
9 constexpr GetTypeId<int> object;
10 return reinterpret_cast<TypeId>(&object);
11 }
I know it is merely valid, because of returning reference to auto variable. Also, because this variable is auto and not static, identifiers will vary, depending on in which function this constexpr object was created (on the stack). Too bad. However, it gave very interesting output, presented on following assembly snippet.1 main:
2 .LFB1:
3 .cfi_startproc
4 leaq -1(%rsp), %rax
5 ret
6 .cfi_endproc
As you can see, there is nothing related to this object variable. At least we don't see this at first glance. GCC is just using the fact that the object is located "above" on the stack. Therefore leaq instruction is used. I was curious whether Clang would behave similarly in this situation:1 main: # @main
2 .cfi_startproc
3 # BB#0:
4 movl $_ZZ4mainE6object, %eax
5 retq
In clang the object has some other address which is not relative to the stack. Interesting. It means that Clang will always allocate space in binary to accommodate this constexpr object. Even if it's not static!
I don't know whether this is a bug in Clang or a bug in GCC. If time permits I'll investigate this further. -
Code::Dive conference

Code::dive conference is over. Emotions subsided. In this post I'd like to summarize this conference from my personal point of view.
There were a lot of extremely interesting talks about C++ and not only. Undoubtedly we had one C++ star on the board - Scott Meyers and I'm going to start with it.
Scott gave two talks CPU Caches and why you care and Support for embedded programming in C++11 and C++14. Both of them were meaningful from perspective of a modern C++ engineer. I encourage you to watch these videos!

 Besides Scott we had our rising C++ stars from Poland: Andrzej Krzemieński and Bartosz Szurgot. Andrzej was talking about bugs in C++ applications. Bartek's talk was about common pitfalls that occur when we do threading in C++. These two talks were also very inspiring so go watch them as well ;)
Besides Scott we had our rising C++ stars from Poland: Andrzej Krzemieński and Bartosz Szurgot. Andrzej was talking about bugs in C++ applications. Bartek's talk was about common pitfalls that occur when we do threading in C++. These two talks were also very inspiring so go watch them as well ;)
I also gave a talk on this conference. My presentation was about Metaprogramming in C++ - from 70's to C++17. As other speaker said - the first time always sucks. And indeed it was my first performance in English. However people are saying that it went quite good so if you have time to waste you can go watch my presentation ;). For the record, slides are here: slideshare.The last thing I'd like to mention was organisation of this conference. It was first that big conference in Wrocław and I can really say that it went perfectly. Big thanks to organizers!
-
Article on Clang internals & Code::Dive conference
Hi, there are two things that I'd like to share with you.
How it's made: Clang C++ compilerThe first one is that I produced one more article for polish developers journal "Programista". This time it is about Clang C++ compiler - how does it work and what's under the bonnet. Unfortunately, it is in Polish, but I promise I'll try to write sth in English soon.
Besides my scribbles you can also find two other interesting articles in current release:
1. Lightweight and portable dispatcher implementation in C++14
This article was written by my workmate Bartosz Szurgot (blog). Not only it describes near-ideal implementation - it also gives some overview on performance issues (useful research, IMHO).
2. C++ Exceptions in details
This in turn is written by Gynvael Coldwind (blog), famous IT security engineer. It is worth reading if you'd like to see how C++ exceptions are really working - in deep details.
Code::DiveThe second thing is my contribution to Code::Dive conference organised by Nokia. The conference is held in Wrocław and I'm going to speak about template metaprogramming in C++. You can find details on the official site.
-
Using static_assert in class-scope
Recently I was working on some presentation (I'm going to post more about this in separate post) and I needed to verify some facts about static_assert in C++11. I decided to look straight in the proposal. Besides information I needed I found that static_assert can be applied in three scopes:- namespace scope
- class scope
- block scope
I must admit that I only knew about the last option. It took me less than a minute to find out that class scope can be useful in case of my project - compile-time state machine (cfsm).One example from cfsm is about ATMs. You can find similar code piece in there.1 namespace cfsm { // cfsm/Transition.hpp
2 template <class StateType, StateType From, StateType To> class Transition;
3 }
4
5 enum class State {
6 Welcome,
7 SelectLanguage,
8 CardError,
9 // ...
10 PrintConfirmation,
11 Invalid
12 };
13
14 template <State From, State To> struct AtmTransition : private cfsm::Transition<State, From, To> { };
15
16 template <> struct AtmTransition<State::Welcome, State::SelectLanguage> { };
17 template <> struct AtmTransition<State::Welcome, State::CardError> { };
18 // ...
19 template <> struct AtmTransition<State::PrintConfirmation, State::Welcome> { };Goal of this piece is to ensure that only defined transitions are possible. If a programmer makes a mistake, the compiler will yell that there's no specialization for given transition. After all, it is a lot better to catch such errors in compile-time, isn't it?However, there are some drawbacks of this mechanism - compiler error messages aren't very readable. Compiler just complains about missing specialization. If the user knows what may be the cause it's not a problem. Otherwise he will be forced to go read header files, which are overloaded with templates. What can we do about it?This is place where class-scope static_assert kicks in. Instead of not providing body for non-specialized transition template we can put one line with some message. It's going to look like following.1 namespace cfsm { // cfsm/Transition.hpp
2 template <class StateType, StateType From, StateType To> class Transition {
3 static_assert(From == To && From != To, "Illegal transition or missing specialization.");
4 }
5 }Note: Unfortunately we need to use such weird condition. Otherwise (e.g. in case of simple false) the compiler would do the assertion ad hoc.There's one more problem to solve. Although custom error message says what the problem is, it doesn't contain enumerator values. This can be split into two separate issues:- Assertion message should be somehow joined by the compiler, basing on multiple constant strings
- Enumerator values need to be represented as strings
It turns out that the later issue is addressed by another C++ proposal - N3815, so let's keep our fingers crossed! Anyway, the first problem is not going to be solved at the moment, which is obviously a bad thing.With this little effort we gained an error message that tells almost everything about the core problem:static.cpp: In instantiation of ‘class cfsm::Transition<State, (State)0, (State)4>’:static.cpp:16:40: required from ‘struct AtmTransition<(State)0, (State)4>’static.cpp:25:51: required from herestatic.cpp:12:5: error: static assertion failed: Illegal transition or missing specialization.static_assert(From == To && From != To, "Illegal transition or missing specialization."); -
Undesirable implicit conversions
Recently Andrzej Krzemienski published a post on his blog about inadvertent conversions. Basically the problem is that sometimes compiler performs implicit conversions (and, as of C++ standard it is allowed to perform at most one) that aren't desired by programmers. In my post I'd like to summarize all solutions that I'm aware of with ones that appeared in comments.
Classical source of such undesirable conversions are non-explicit constructors accepting exactly one non-default parameter. However, in this example there's a need to disable particular converting constructors while still accepting desired ones. Consider following piece of code:1 struct C {
2 C(int const n) {}
3 };
4
5 int main(void) {
6 C fromInt = 5; // Okay
7 C fromDouble = 5.5; // Potentially not desired
8 }
This kind of problem occurs in boost::rational library, as Andrzej mentions. Okay, so what are the solutions? The first one is pretty obvious - let's explicitly delete all constructors accepting double as parameter.1 struct C {
2 C(int const n) {}
3 C(double const x) = delete;
4 };
5
6 int main(void) {
7 C fromInt = 5; // Okay
8 C fromDouble = 5.5; // Illegal!
9 }
The solution is pretty straightforward and it addresses the problem basing on type, not type traits - which can be a problem in some contexts. There is another solution that lacks this particular problem. It employs enable_if to make sure only integral types can be used with our converting constructors.1 #include <type_traits>
2 using namespace std;
3
4 struct C {
5 template <typename T, typename enable_if<is_integral<T>::value, int>::type = 0>
6 C(T const n) {}
7 };
8
9 int main(void) {
10 C fromInt = 5; // Okay
11 C fromDouble = 4.0; // Illegal!
12 }
It is elegant and it does the job well. However, in my humble opinion there's one area of improvement - diagnostics and readability. If we used static_assert error message produces by the compiler would be a lot more readable to the programmer. Also, the code would become more clear and the intentions would be visible at first sight.1 #include <type_traits>
2 using namespace std;
3
4 struct C {
5 template <typename T>
6 C(T const n) {
7 static_assert(is_integral<T>::value, "Only integral values are supported!");
8 }
9 };
10
11 int main(void) {
12 C fromInt = 5;
13
14 // error: static_assert failed "Only integral values are supported!"
15 C fromDouble = 4.0;
16 }
Do you know any issues that can appear with last solution? If yes please share them in comments, please ;)
Interestingly, when you compile example from the first listing on Clang (3.5, trunk 196051) you'll get an warning that implicit conversion is being used. GCC (4.8.2) stays quiet about that. This is another proof that clang is more user-friendly compiler.
-
Pointers to class members and their addresses
Today I was trying to help my work mate to design sort of unit testing helper. Basically it was about function pointers to virtual methods. Pointers to functions take virtuality into account when they are called with a reference or a pointer to the base class. The thing is that before I made my point, we have decided to check one simple thing.
So here's a puzzle for you. Given following code (and without using a compiler) try to answer following questions.1 #include <iostream>
2 using namespace std;
3
4 struct A {
5 virtual void foo() {}
6 };
7
8 struct B : A {
9 virtual void foo() {}
10 };
11
12 int main(void) {
13 cout << hex << &A::foo << endl;
14 cout << hex << &B::foo << endl;
15 }
1. Will this code compile?
2. If yes, what will be the addresses of A::foo and B::foo methods, respectively?
3. If yes, what will be the output of this program?
Did you think about it? Remember... there's no hurry ;-).
Answer to the first question is positive as the code is well-formed C++. What about addresses of methods? C++ requires that every method has it's own unique place to live - an address (or offset). Virtuality does not change anything here, so we can assume that these addresses are some integers, let's say a and b.
The last question is the most tricky one. While intuition suggests that the output might look like following, it's not true at all.
0x00c0d150
0x00c0d15c
The real output of the program is:
1
1
What a surprise, right? The catch in above code fragment is that there's no overloaded function accepting function pointer for ostream. What the compiler can do instead? It can use implicit conversion. It turns out that there's implicit conversion from function pointer to a boolean. This would spill out if we used std::boolalpha flag, but who knew?
I'd like to ask you one more question: what if we used reinterpret_cast<void*> against member pointers in lines 13-14? Would the output have gotten right then?
Surprisingly, the code would not compile then. The reason for that are some machines that hold code and data memory in different locations. Therefore, it's hard to specify a portable way to convert between pointers to the data and pointers to the code.
The funny fact is that clang does not compile it, while GCC only issues a warning.

slawomir.net
I'm a Linux Hooligan and this blog is about funny, interesting and weird faces of Software Engineering.