
Real Boost.multi_index performance

Update 09.05.2015: thanks to Joaquín it turned out that I had slight bug in my plotting script - x tick labels were wrong. All pictures have been fixed.
Several months ago I prepared and conducted a presentation about multi_index library from Boost at Nokia TechMeetUp. Essentially I showed that it is pretty useful library that should be used when there's a need to represent the same data with multiple "views". For instance, if we have to access the same list of something sorted by different attributes, Boost.MultiIndex seems to be very good choice as the documentation claims strong consistency and, what's also important, better performance. What's also interesting is that Facebook's library - folly - utilizes that in its TimeoutQueue class.
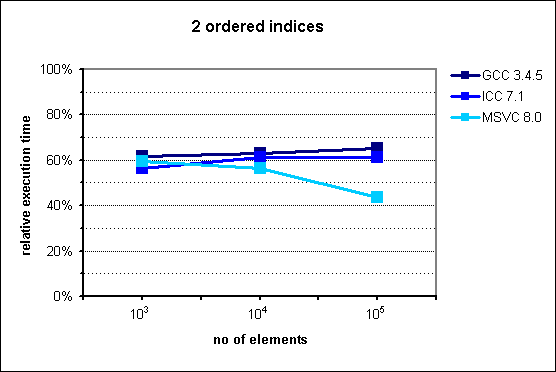
In the middle of the presentation I put some performance graphs which I mindlessly copied them from the documentation. Had I known that they are old, I'd never do that. Fortunately it was pointed out by friend of mine. These graphs in fact illustrate performance gains, but measurements were made with ancient compiler versions like GCC 3.4.5.
After the presentation I promised myself that I'll investigate this a bit, but as usual time didn't permit. Till now.
I made measurements with newer versions of GCC and Clang. Unfortunately I have no access to Visual Studio. If you can provide me VS stats I'd be pleased, though.
Here are my results for:
CPU: i5-3320M
RAM: 8GB
OS: Debian 7
Compilation flags: -O3
Boost version: 1.57
Images from documentation are placed at the right side.
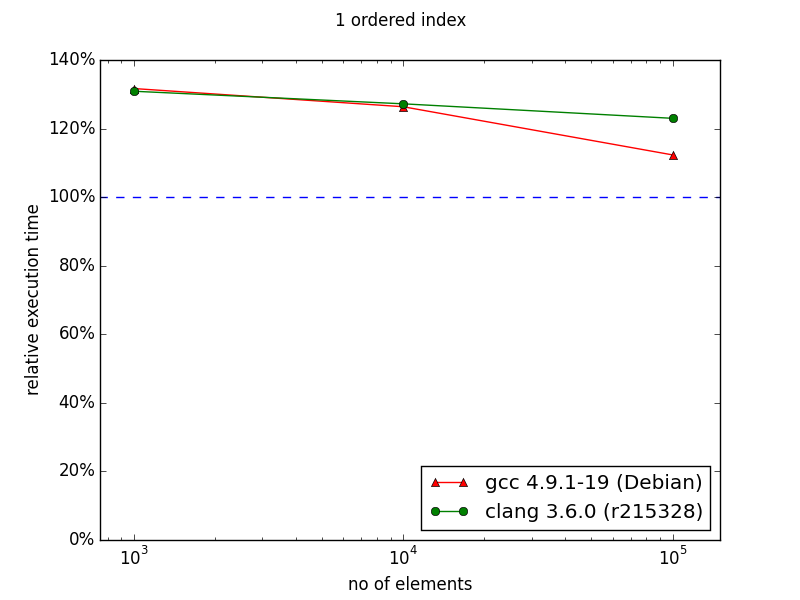
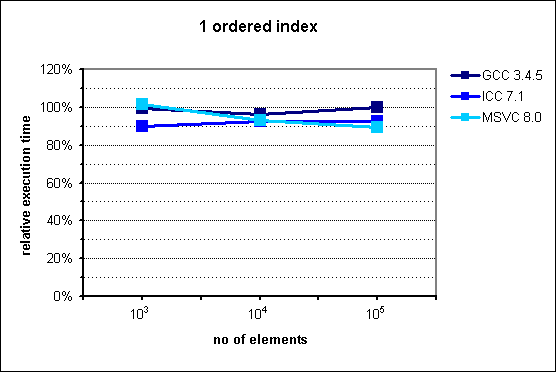
In the case of ordered index it's visible that either standard containers were improved or compilers learned how to optimize code using them better. Nevertheless, there is visible trend showing that with more than 106 entries, multi_index container could perform better than naive approach.
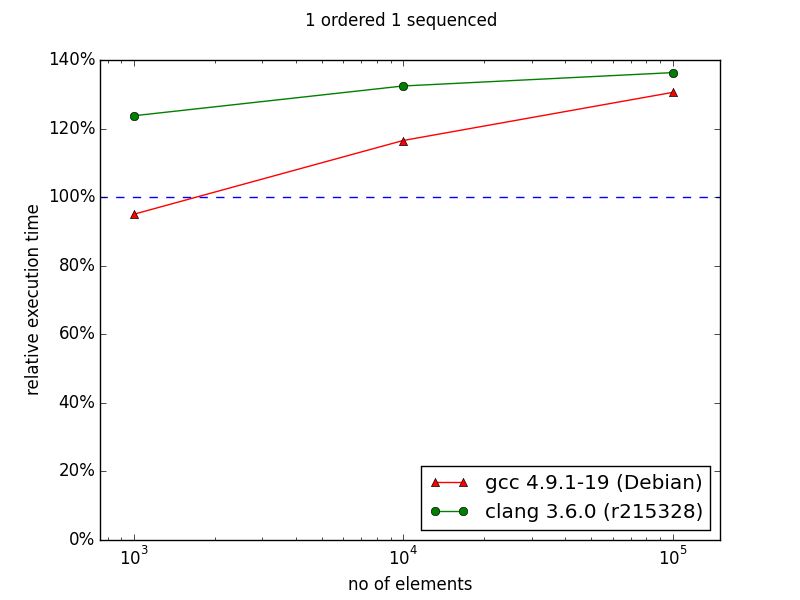
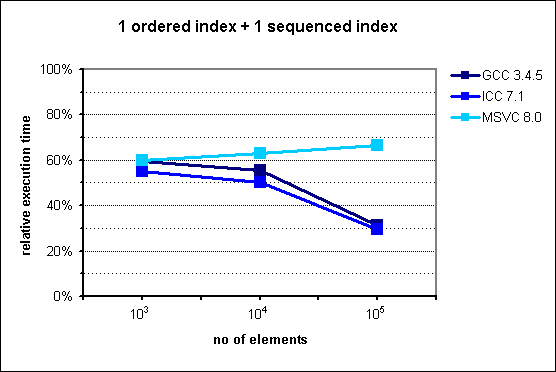
In case of two indexes - one indexed and the second sequenced situation changes. In the original chart from the documentation we can observe huge improvement in favor to multi_index starting from 105 elements. My results are quite different - there is no performance gain with multi_index. For 106 elements the difference is dramatic comparing the two diagrams: ~130% and ~30%.
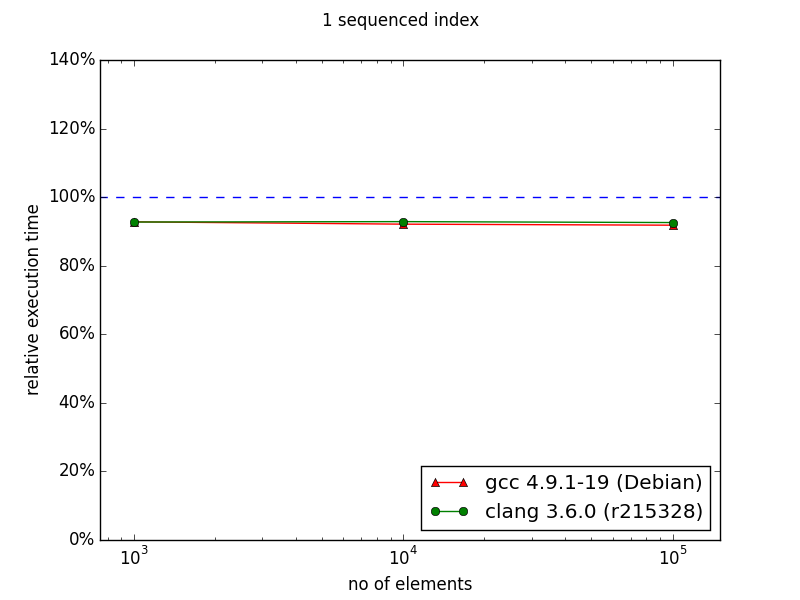
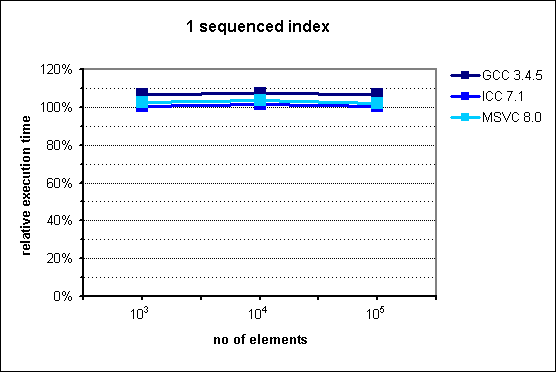
Rest of diagrams are presented below. As you can see they illustrate that multi_index documentation is outdated. Sometimes there are some performance gains, but not that huge as presented in diagrams from documentation.
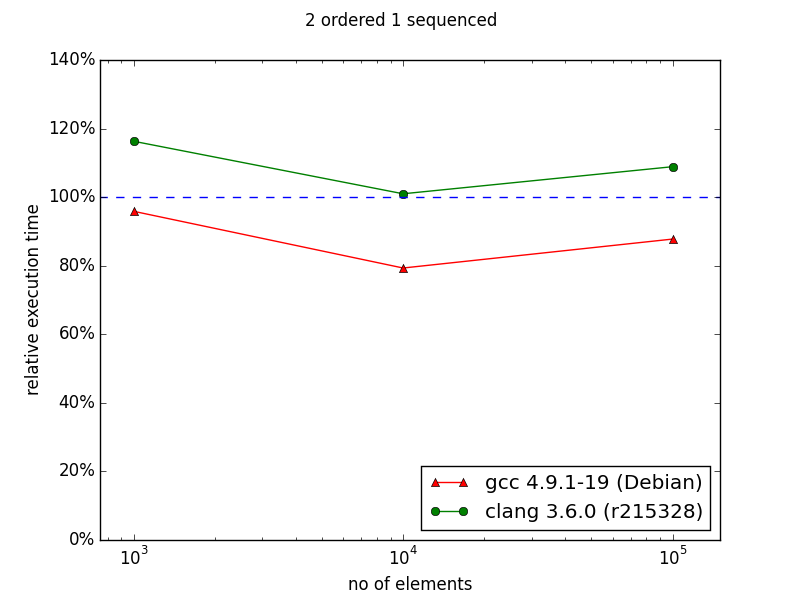
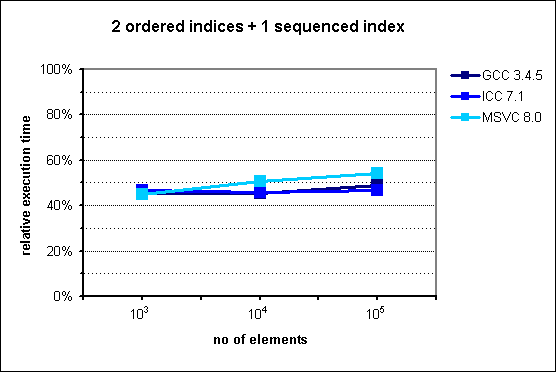
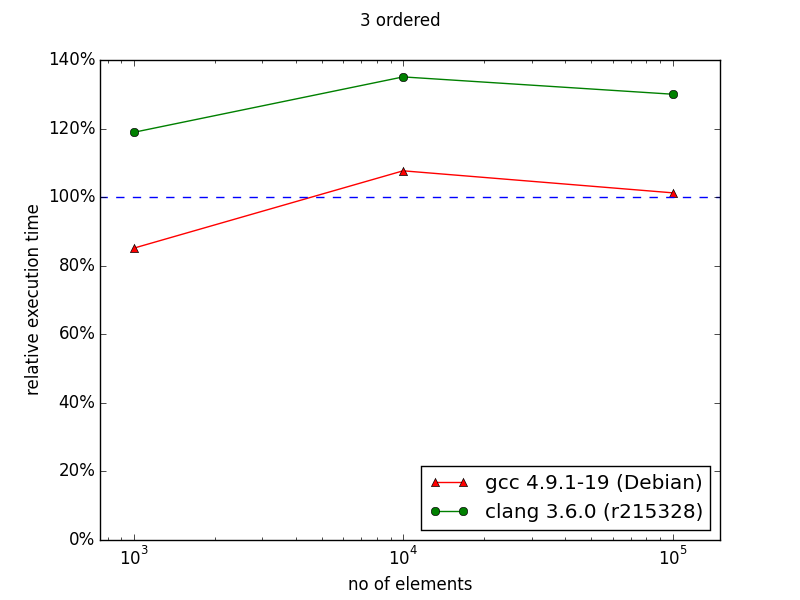

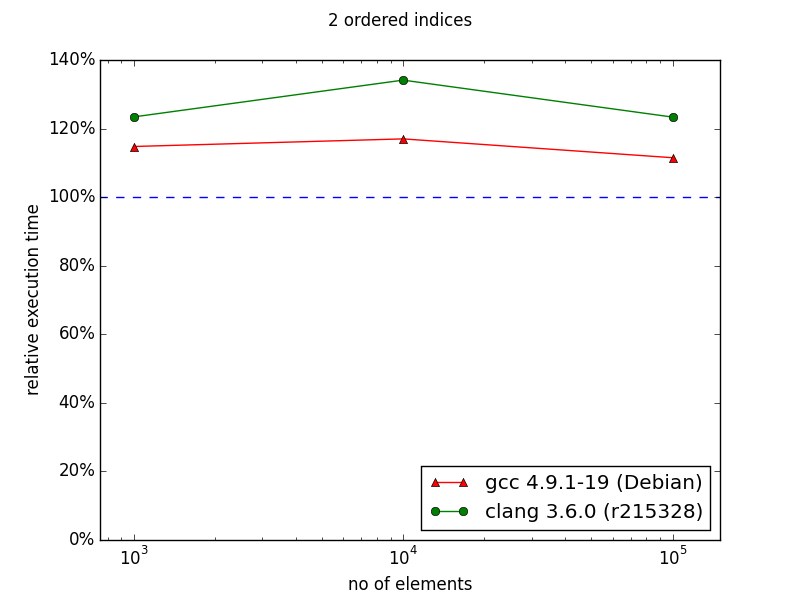
Unfortunately currently I have no time to dig in into this. (Maybe in next days I'll have some time to check how cache-friendly multi_index library is). Nevertheless, everything that I showed pushes me even harder into opinion that everything should be measured - even 3rd-party things with a lot of promises in the documentation.
