-
Airflow Docker with Xcom push and pull
Recently, in one projects I'm working on, we started to research technologies that can be used to design and execute data processing flows. Amount of data to be processed is counted in terabytes, hence we were aiming at solutions that can be deployed in the cloud. Solutions from Apache umbrella like Hadoop, Spark, or Flink were at the table from the very beginning, but we also looked at others like Luigi or Airflow, because our use case was neither MapReducable nor stream-based.
Airflow caught our attention and we decided to give it a shot just to see if we can create PoC using it*. In order to execute PoC faster rather than slower, we planned to provision Swarm cluster for this.
In the Airflow you can find couple of so-called operators that allow you to execute actions. There are operators for Bash or Python, but you can also find something for e.g. Hive. Fortunately there is also Docker operator for us.
Local PoC
PoC started on my laptop and not in the cluster. Thankfully, DockerOperator allows you to pass URL to docker daemon, so moving from laptop to cluster is close to just changing one parameter. Nice!
If you want to run Airflow server locally from inside container, and have it running as non-root (you should!) and you bind docker.sock from host to the container, you must create docker group in the container that mirrors docker group on your host and then add e.g. airflow user to this group. That does the trick...
So just running DockerOperator is not black magic. However, if your containers need to exchange data it starts to be a little bit more tricky.
Xcom push/pull
The push part is simple and documented. Just set xcom_push parameter to True and last line of container stdout will be published by Airflow as it was pushed programatically. It looks that this is natural Airflow way.
Pull is not that obvious. Perhaps because it's not documented. You can't read stdin or something. The way to do this involves joining two dots:- command parameter can be Jinja2-templated
- one of the macros allows you to do xcom_pull
FROM debian
ENTRYPOINT echo '{"i_am_pushing": "json"}'
Simple enough. Now pulling container:
FROM debian
COPY ./entrypoint /
ENTRYPOINT ["/entrypoint"]
Entrypoint script can be whatever and will get the JSON as $1. Crucial (and also easy to miss) thing that is required for it to work is that ENTRYPOINT must use exec form. Yes, there are two forms of ENTRYPOINT. If you use the one without array, then parameters will not be passed to the container!
Finally, you can glue things together and you're done. The ti macro allows us to get data pushed by other task. ti stands for task_instance.
dag = DAG('docker', default_args=default_args, schedule_interval=timedelta(1))
t1 = DockerOperator(task_id='docker_1', dag=dag, image='docker_1', xcom_push=True)
t2 = DockerOperator(task_id='docker_2', dag=dag, image='docker_2', command='{{ ti.xcom_pull(task_ids="docker_1") }}')
t2.set_upstream(t1)
Conclusion
Docker can be used in Airflow along with Xcom push/pull functionality. It isn't very convenient and is not well documented I would say, but at least it works.
If time permits I'm going to create PR for documenting pull op. I don't know how it works out, because in Airflow GH project there are 237 PRs now and some of them are there since May 2016!
* the funny thing is that we considered Jenkins too! ;-) -
Tests stability S09E11 (Docker, Selenium)
If you're experienced in setting up automated testing with Selenium and Docker you'll perhaps agree with me that it's not the most stable thing in the world. Actually it's far far away from any stable island - right in the middle of "the sea of instability".
When you think about failures in automated testing and how they develop when the system is growing it can resemble drugs. Seriously. When you start, occasional failures are ignored. You close your eyes and click "Retry". Innocent. But after some time it snowballs into a problem. And you find yourself with a blind fold put on but you can't remember buying it.
This post is small story how in one of small projects we started with occasional failures and ended up with... well... you'll see. Read on ;).
For past couple of months I was thinking that "others have worse setups and live", but today it all culminated, I have achieved fourth degree of density and decided to stop being quiet.
Disclaimer
In the middle of this post you might start to think that our environment is simply broken. That's damn right. The cloud in which we're running is not very stable. Sometimes it behaves like it had a sulk. There are problems with proxies too. And finally we add Docker and Selenium to the mixture. I think testimonial from one of our engineers sums it all:if retry didn’t fix it for the 10th time, then there’s definitely something wrong
And now something must be noted as well. The project I'm referring to is just a sideway one. It's an attempt to innovate some process, unsupported by the business whatsoever.
The triggers
I was pressing "Retry" button for another time on two of the e2e jobs and saw following.
// job 1
couldn't stat /proc/self/fd/18446744073709551615: stat /proc/self/fd/23: no such file or directory
// job 2
Service 'frontend' failed to build: readlink /proc/4304/exe: no such file or directory
What the hell is this? We have never seen this before and now apparently it became a commonplace in our CI pipeline (it was nth retry).
So this big number after /fd/ is 64-bit value of -1. Perhaps something in Selenium uses some function that returns an error and then tries to call stat syscall, passing -1 as an argument. Function return value was not checked!
The second error message is most probably related to docker. Something tries to find where is executable for some PID. Why?
"Retry" solution did not work this time. Re-deploying e2e workers also didn't help. I thought that now is the time when we should get some insights into what is actually happening and how many failures were caused by unstable environment.
Luckily we're running on GitLab, which provides reasonable API. Read on to see what I've found. I personally find it hilarious.
Insight into failures
It's extremely easy to make use of GitLab CI API (thanks GitLab guys!). I have extracted JSON objects for every job in every pipeline that was recorded in our project and started playing with the data.
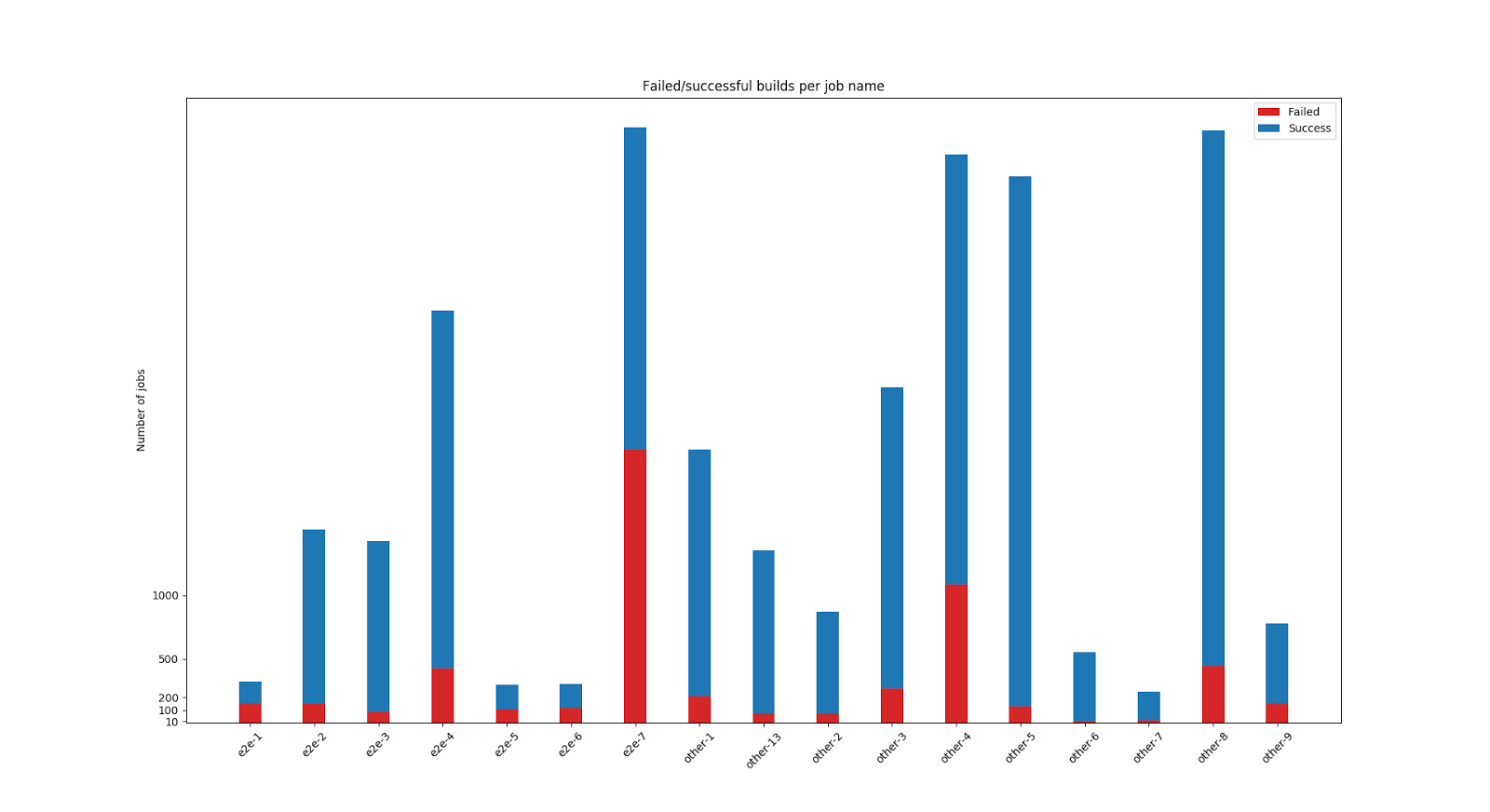
The first thing that I checked was how many failures there are per particular type of test. Names are anonymized a little because I'm unsure if this is sensitive data or not. Better safe than sorry!
I knew that some tests were failing often, but these results tell that in some cases almost 50% of the jobs fail! Insane! BTW we recently split some of long-running e2e test suites into smaller jobs, which is observable from the figure.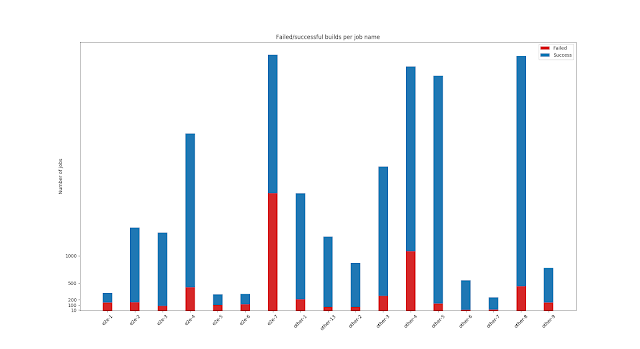
Fig 1: Successful/failed jobs, per job name
But now we can argue that maybe this is because of the bugs in the code. Let's see. In order to tell this we must analyze data basing on commit hashes: how many commits in particular jobs were executed multiple times and finished with different status. In other words: we look for the situations in which even without changes in the code the job status was varying.
The numbers for our repository are:- number of (commit, job) pairs with at least one success: 23550
- total number of failures for these pairs: 1484
In other words, unstable environment was responsible for at least ~6.30% of observable failures. It might look like small number, but if you take into account that single job can last for 45 minutes, it becomes a lot of wasted time. Especially that failure notifications aren't always handled immediately. I also have a hunch that at some time people started to click "Retry" just to be sure the problem is not with the environment.
My top 5 picks among all of these failures are below.
hash:job | #tot | success/fail | users clicking "Retry"
----------------------------------------------------------------
d7f43f9c:e2e-7 | 19 | ( 1/17) | user-6,user-7,user-5
2fcecb7c:e2e-7 | 16 | ( 8/ 8) | user-6,user-7
2c34596f:other-1 | 14 | ( 1/13) | user-8
525203c6:other-13 | 12 | ( 1/ 8) | user-13,user-11
3457fbc5:e2e-6 | 11 | ( 2/ 9) | user-14
So, for instance - commit d7f43f9c was failing on job e2e-7 17 times and three distinct users tried to make it pass by clicking "Retry" button over and over. And finally they made it! Ridiculous, isn't it?
And speaking of time I've also checked jobs that lasted for enormous number of time. Winners are:
job:status | time (hours)
---------------------------------
other-2:failed | 167.30
other-8:canceled | 118.89
other-4:canceled | 27.19
e2e-7:success | 26.12
other-1:failed | 26.01
Perhaps these are just outliers. Histograms would give better insight. But even if outliers, they're crazy outliers.
I have also attempted to detect reason of the failure but this is more complex problem to solve. It requires to parse logs and guess which line was the first one indicating error condition. Then the second guess - about whether the problem originated from environment or the code.
Maybe such a task could be somehow handled by (in)famous machine learning. Actually there are more items that could be achieved with ML support. Two most simple examples are:- giving estimation whether the job will fail
- also, providing reason of failure
- if the failure originated from faulty environment, what exactly was it?
- estimated time for the pipeline to finish
- auto-retry in case of env-related failure
Conclusions
Apparently I've been having much more unstable e2e test environment than I ever thought. Lesson learned is that if you get used to solve problem by retrying you loose sense in how big trouble you are.
Similarly to any other engineering problem you first need to gather data and decide what to do next. Basing on numbers I have now I'm planning to implement some ideas to make life easier.
While analyzing the data I had moments when I couldn't stop laughing to myself. But the reality is sad. It started with occasional failures and ended with continuous problem. And we weren't doing much about it. The problem was not that we were effed in the ass. The problem was that we started to arrange our place there. Insights will help us get out.
Share your ideas in comments. If we bootstrap discussion I'll do my best to share the code I have in GitHub. -
C++: on the dollar sign
In most programming languages there are sane rules that specify what can be an identifier and what cannot. Most of the time it's even intuitive - it's just something that matches [_a-zA-Z][a-zA-Z0-9]*. There are languages that allow more (e.g. $ in PHP/JS, or % in LabTalk). How about C++? Answer to this question may be a little surprise.
Almost a year ago we had this little argument with friend of mine whether dollar sign is allowed to be used within C++ identifiers. In other words it was about whether e.g. int $this = 1; is legal C++ or not.
Basically I was stating that's not possible. On the other hand, my friend was recalling some friend of his, which mentioned that dollars are fine.
The first line of defense is of course nearest compiler. I decided to fire up one and simply check what happens if I compile following fragment of code.1 auto $foo() {
2 int $bar = 1;
3 return $bar;
4 }
At the time I had gcc-4.9.3 installed on my system (prehistoric version, I know ;-). For the record, the command was like this: g++ dollar.cpp -std=c++1y -c -Wall -Wextra -Werror.
And to my surprise... it compiled without single complaint. Moreover, clang and MSVC gulped this down without complaining as well. Well, Sławek - I said to myself - even if you're mastering something for years, there's still much to surprise you. BTW such a conclusion puts titles like following in much funnier light.
It was normal office day and we had other work to get done, so I reluctantly accepted this just as another dark corner. After couple of hours I forgot about the situation and let it resurface... couple of weeks later.
So, fast forward couple of weeks. I was preparing something related to C++ and I accidentally found a reference to the dollar sign in GCC documentation. It was nice feeling, because I knew I will fill this hole in my knowledge in a matter of minutes. So what was the reason compilers were happily accepting dollar signs?
Let me put here excerpt from GCC documentation, which speaks for itself :)GCC allows the ‘$’ character in identifiers as an extension for most targets. This is true regardless of the std= switch, since this extension cannot conflict with standards-conforming programs. When preprocessing assembler, however, dollars are not identifier characters by default.
Currently the targets that by default do not permit ‘$’ are AVR, IP2K, MMIX, MIPS Irix 3, ARM aout, and PowerPC targets for the AIX operating system.
You can override the default with -fdollars-in-identifiers or fno-dollars-in-identifiers. See fdollars-in-identifiers.
I think three most important things are:- This ain't work in macros.
- It doesn't seem to be correlated with -std switch.
- Some architectures do not permit it at all.
GCC could theoretically mitigate problem with particular architectures by replacing $ signs with some other character, but then bunch of other problems would appear: possible name conflicts, name mangling/demangling would yield incorrect values, and finally it wouldn't be possible to export such "changed" symbols from a library. In other words: disaster.
What about the standard?
After thinking about it for a minute I had strong need to see what exactly identifier does mean. So I opened N3797 and quickly found section I was looking for, namely (surprise-surprise) 2.11 Identifiers. So what does this section say?
Right after formal definition there is an explanation which refers to sections E.1 and E.2. But that's not important here. There is one more thing that appears in the formal definition and it's extremely easy to miss this one. It's "other implementation-defined characters". What does it mean? Yup - the compiler is allowed to allow any other character to be used within identifiers at will.
P.s. surprisingly cppcheck 1.71 doesn't report $ sign in identifiers as a problem at all. -
Getting all parent directories of a path
edit: reddit updates
Few minutes ago I needed to solve trivial problem of getting all parent directories of a path. It's very easy to do it imperatively, but it would simply not satisfy me. Hence, I challenged myself to do it declaratively in Python.
The problem is simple, but let me put an example on the table, so it's even easier to imagine what are we talking about.
Given some path, e.g.
/home/szborows/code/the-best-project-in-the-world
You want to have following list of parents:
/home/szborows/code
/home/szborows
/home
/
It's trivial to do this using split and then some for loop. How to make it more declarative?
Thinking more mathematically (mathematicians will perhaps cry out to heaven for vengeance after reading on, but let me at least try...) we simply want to get all of the subsets from some ordered set S that form prefix w.r.t. S. So we can simply generate pairs of numbers (1, y), representing all prefixes where y belongs to [1, len S). We can actually ignore this constant 1 and just operate on numbers.
In Python, to generate numbers starting from len(path) and going down we can simply utilize range() and [::-1] (this reverses collections, it's an idiom). Then join() can be used on splited path, but with slicing from 1 to y. That's it. And now demonstration:
>>> path = '/a/b/c/d'
>>> ['/' + '/'.join(path.split('/')[1:l]) for l in range(len(path.split('/')))[::-1] if l]
['/a/b/c', '/a/b', '/a', '/']
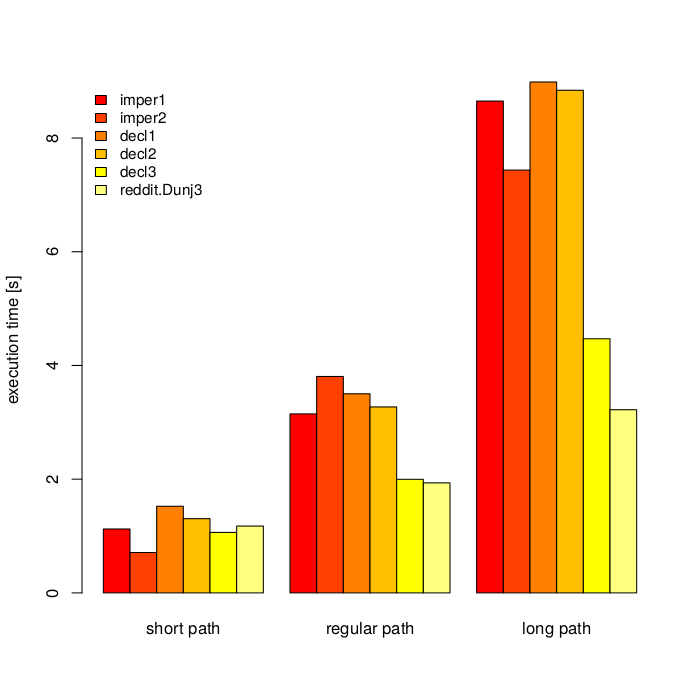
But what about performance? Which one will be faster - imperative or declarative approach? Intuition suggests that imperative version will win, but let's check.
On picture below you can see timeit (n=1000000) results for my machine (i5-6200U, Python 3.5.2+) for three paths:short_path = '/lel'
regular_path = '/jakie/jest/srednie/zagniezdzenie?'
long_path = '/z/lekka/dlugasna/sciezka/co/by/pierdzielnik/mial/troche/roboty'Implementations used: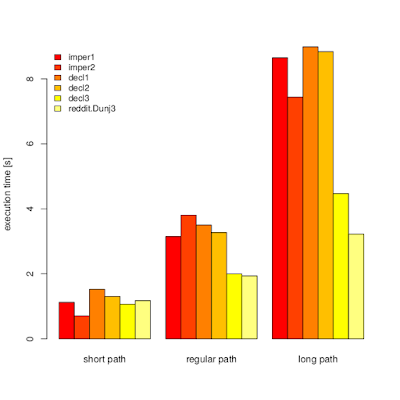
def imper1(path):
result = []
for i in range(1, len(path.split('/'))):
y = '/'.join(path.split('/')[:i]) or '/'
result.append(y)
return result
def imper2(path):
i = len(path) - 1
l = []
while i > 0:
while i != 0 and path[i] != '/':
i -= 1
l.append(path[:i] or '/')
i -= 1
return l
def decl1(path):
return ['/' + '/'.join(path.split('/')[1:l])for l in range(len(path.split('/')))[::-1] if l]
def decl2(path):
return ['/' + '/'.join(path.split('/')[1:-l])for l in range(-len(path.split('/'))+1, 1) if l]
# decl3 hidden. read on ;-)
It started with imper1 and decl1. I noticed that imperative version is faster. I tried to speed up declarative function by replacing [::-1] with some numbers tricks. It helped, but not to the extend I anticipated. Then, I though about speeding up imper1 by using lower-level constructs. Unsurprisingly while loops and checks were faster. Let me temporarily ignore decl3 for now and play a little with CPython bytecode.
By looking at my results not everything is so obvious. decl{1,2} turned out to have decent performance with 4-part path, which looks like reasonable average.
I disassembled decl1 and decl2 to see the difference in byte code. The diff is shown below.
30 CALL_FUNCTION 1 (1 positional, 0 keyword pair) | 30 CALL_FUNCTION 1 (1 positional, 0 keyword pair)
33 CALL_FUNCTION 1 (1 positional, 0 keyword pair) | 33 CALL_FUNCTION 1 (1 positional, 0 keyword pair)
36 CALL_FUNCTION 1 (1 positional, 0 keyword pair) | 36 UNARY_NEGATIVE
39 LOAD_CONST 0 (None) | 37 LOAD_CONST 4 (1)
42 LOAD_CONST 0 (None) | 40 BINARY_ADD
45 LOAD_CONST 5 (-1) | 41 LOAD_CONST 4 (1)
48 BUILD_SLICE 3 | 44 CALL_FUNCTION 2 (2 positional, 0 keyword pair)
51 BINARY_SUBSCR
As we can see [::-1] is implemented as three loads and build slice operations. I think this could be optimized if we had special opcode like e.g. BUILD_REV_SLICE. My little-optimized decl2 is faster because one UNARY_NEGATIVE and one BINARY_ADD is less than LOAD_CONST, BUILD_SLICE and BINARY_SUBSCR. Performance gain here is pretty obvious. No matter what decl2 must be faster.
What about decl2 vs imper1?
It's more complicated and it was a little surprise that such a longer bytecode can be slower than shorter counterpart.
3 0 BUILD_LIST 0
3 STORE_FAST 1 (result)
4 6 SETUP_LOOP 91 (to 100)
9 LOAD_GLOBAL 0 (range)
12 LOAD_CONST 1 (1)
15 LOAD_GLOBAL 1 (len)
18 LOAD_FAST 0 (path)
21 LOAD_ATTR 2 (split)
24 LOAD_CONST 2 ('/')
27 CALL_FUNCTION 1 (1 positional, 0 keyword pair)
30 CALL_FUNCTION 1 (1 positional, 0 keyword pair)
33 CALL_FUNCTION 2 (2 positional, 0 keyword pair)
36 GET_ITER
>> 37 FOR_ITER 59 (to 99)
40 STORE_FAST 2 (i)
5 43 LOAD_CONST 2 ('/')
46 LOAD_ATTR 3 (join)
49 LOAD_FAST 0 (path)
52 LOAD_ATTR 2 (split)
55 LOAD_CONST 2 ('/')
58 CALL_FUNCTION 1 (1 positional, 0 keyword pair)
61 LOAD_CONST 0 (None)
64 LOAD_FAST 2 (i)
67 BUILD_SLICE 2
70 BINARY_SUBSCR
71 CALL_FUNCTION 1 (1 positional, 0 keyword pair)
74 JUMP_IF_TRUE_OR_POP 80
77 LOAD_CONST 2 ('/')
>> 80 STORE_FAST 3 (y)
6 83 LOAD_FAST 1 (result)
86 LOAD_ATTR 4 (append)
89 LOAD_FAST 3 (y)
92 CALL_FUNCTION 1 (1 positional, 0 keyword pair)
95 POP_TOP
96 JUMP_ABSOLUTE 37
>> 99 POP_BLOCK
7 >> 100 LOAD_FAST 1 (result)
103 RETURN_VALUE
The culprit was LOAD_CONST in decl{1,2} that was loading list-comprehension as a code object. Let's see how it looks, just for the record.
>>> dis.dis(decl2.__code__.co_consts[1])
21 0 BUILD_LIST 0
3 LOAD_FAST 0 (.0)
>> 6 FOR_ITER 51 (to 60)
9 STORE_FAST 1 (l)
12 LOAD_FAST 1 (l)
15 POP_JUMP_IF_FALSE 6
18 LOAD_CONST 0 ('/')
21 LOAD_CONST 0 ('/')
24 LOAD_ATTR 0 (join)
27 LOAD_DEREF 0 (path)
30 LOAD_ATTR 1 (split)
33 LOAD_CONST 0 ('/')
36 CALL_FUNCTION 1 (1 positional, 0 keyword pair)
39 LOAD_CONST 1 (1)
42 LOAD_FAST 1 (l)
45 UNARY_NEGATIVE
46 BUILD_SLICE 2
49 BINARY_SUBSCR
50 CALL_FUNCTION 1 (1 positional, 0 keyword pair)
53 BINARY_ADD
54 LIST_APPEND 2
57 JUMP_ABSOLUTE 6
>> 60 RETURN_VALUE
So this is how list comprehensions look like when converted to byte code. Nice! Now performance results make more sense. In the project I was working on my function for getting all parent paths was called in one place and perhaps contributed to less than 5% of execution time of whole application. It would not make sense to optimize this piece of code. But it was delightful journey into internals of CPython, wasn't it?
Now, let's get back to decl3. What have I done to make my declarative implementation 2x faster on average case and for right-part outliers? Well... I just reluctantly resigned from putting everything in one line and saved path.split('/') into separate variable. That's it.
So what are learnings?- declarative method turned out to be faster than hand-crafter imperative one employing low-level constructs.
Why? Good question! Maybe because bytecode generator knows how to produce optimized code when it encounters list comprehension? But I have written no CPython code, so it's only my speculation. - trying to put everything in one line can hurt - in described case split() function was major performance dragger
Dunj3 outpaced me ;) - his implementation, which is better both w.r.t. "declarativeness" and performance:list(itertools.accumulate(path.split('/'), curry(os.sep.join)))
syntax highlighting done with https://tohtml.com/python/ - declarative method turned out to be faster than hand-crafter imperative one employing low-level constructs.
-
Logstash + filebeat: Invalid Frame Type, received: 1
Post for googlers that stumble on the same issue - it seems that "overconfiguration" is not a great idea for Filebeat and Logstash.
I've decided to explicitly set ssl.verification_mode to none in my Filebeat config and then I got following Filebeat and Logstash errors:
filebeat_1 | 2017/01/03 07:43:49.136717 single.go:140: ERR Connecting error publishing events (retrying): EOF
filebeat_1 | 2017/01/03 07:43:50.152824 single.go:140: ERR Connecting error publishing events (retrying): EOF
filebeat_1 | 2017/01/03 07:43:52.157279 single.go:140: ERR Connecting error publishing events (retrying): EOF
filebeat_1 | 2017/01/03 07:43:56.173144 single.go:140: ERR Connecting error publishing events (retrying): EOF
filebeat_1 | 2017/01/03 07:44:04.189167 single.go:140: ERR Connecting error publishing events (retrying): EOF
logstash_1 | 07:42:35.714 [Api Webserver] INFO logstash.agent - Successfully started Logstash API endpoint {:port=>9600}
logstash_1 | 07:43:49.135 [nioEventLoopGroup-4-1] ERROR org.logstash.beats.BeatsHandler - Exception: org.logstash.beats.BeatsParser$InvalidFrameProtocolException: Invalid Frame Type, received: 3
logstash_1 | 07:43:49.139 [nioEventLoopGroup-4-1] ERROR org.logstash.beats.BeatsHandler - Exception: org.logstash.beats.BeatsParser$InvalidFrameProtocolException: Invalid Frame Type, received: 1
logstash_1 | 07:43:50.150 [nioEventLoopGroup-4-2] ERROR org.logstash.beats.BeatsHandler - Exception: org.logstash.beats.BeatsParser$InvalidFrameProtocolException: Invalid Frame Type, received: 3
logstash_1 | 07:43:50.154 [nioEventLoopGroup-4-2] ERROR org.logstash.beats.BeatsHandler - Exception: org.logstash.beats.BeatsParser$InvalidFrameProtocolException: Invalid Frame Type, received: 1
logstash_1 | 07:43:52.156 [nioEventLoopGroup-4-3] ERROR org.logstash.beats.BeatsHandler - Exception: org.logstash.beats.BeatsParser$InvalidFrameProtocolException: Invalid Frame Type, received: 3
logstash_1 | 07:43:52.157 [nioEventLoopGroup-4-3] ERROR org.logstash.beats.BeatsHandler - Exception: org.logstash.beats.BeatsParser$InvalidFrameProtocolException: Invalid Frame Type, received: 1
logstash_1 | 07:43:56.170 [nioEventLoopGroup-4-4] ERROR org.logstash.beats.BeatsHandler - Exception: org.logstash.beats.BeatsParser$InvalidFrameProtocolException: Invalid Frame Type, received: 3
logstash_1 | 07:43:56.175 [nioEventLoopGroup-4-4] ERROR org.logstash.beats.BeatsHandler - Exception: org.logstash.beats.BeatsParser$InvalidFrameProtocolException: Invalid Frame Type, received: 1
It seems it's better to stay quiet with Filebeat :) Hopefully this helped to resolve your issue. -
std::queue's big default footprint in assembly code
Recently I've been quite busy and now I'm kind of scrounging back into C++ world. Friend of mine told me about IncludeOS project and I thought that it may be pretty good exercise to put my hands on my keyboard and help in this wonderful project.
To be honest, the learning curve is quite steep (or I'm getting too old to learn so fast) and I'm still distracted by a lot of other things, so no big deliverables so far... but by just watching discussion on Gitter and integrating it with what I know I spotted probably obvious, but a little bit surprising thing about std::queue.
std::queue is not a container. Wait, what?, you ask. It's a container adapter. It doesn't have implementation. Instead, it takes other implementation, uses it as underlying container and just provides some convenient interface for end-user. By the way it isn't the only one. There are others like std::stack and std::priority_queue to name a few.
One of the dimension in which C++ shines are options for customizing stuff. We can customize things like memory allocators. In container adapters we can customize this underlying container if we decide that the one chosen by library writers isn't good match for us.
By default, perhaps because std::queue requires fast access at the beginning and end, it's underlying container is std::deque. std::deque provides O(1) complexity for pushing/popping at both ends. Perfect match, isn't it?
Well, yes if you care about performance at the cost of increased binary size. As it turns out by simply changing std::deque to std::vector:
std::queue<int> qd;
std::queue<int, std::vector<int>> qv;
Generated assembly code for x86-64 clang 3.8 (-O3 -std=c++14) is 502 and 144 respectively.
I know that in most context binary size is secondary consideration, but still I believe it's an interesting fact that the difference is so big. In other words there must be a lot of things going on under the bonnet of std::deque. I don't recommend changing deque to vector in production - it can seriously damage your performance.
You can play around with the code here: https://godbolt.org/g/XaLhS7 (code based on Voultapher example). -
elasticdiff
Recently I needed to compare two ElasticSearch indices. To be honest I was pretty sure that I'll find something in the Internet. It was a surprise that no such a tool do exist. I thought that this is good time to pay off portion of my debt to open-source :)Enter ElasticDiff
elasticdiff is a simple project hosted on GitHub which allows you to compare two ES indices without pain. It is early development, so don't expect much, but for simple indices it works pretty well.
Usage is quite trivial:
python3 elasticdiff.py -t docType -i key http://1.2.3.4/index1 http://2.3.4.5/index1
Output was designed to imitate diff command:only in left: a5
only in left: a1
only in right: a4
only in right: a2
entries for key a3 differ
---
+++
@@ -1,4 +1,4 @@
{
"key": "a3",
- "value": "DEF"
+ "value": "XYZ"
}
Summary:
2 entries only in left index
2 entries only in right index
1 common entries
0 of them are the same
1 of them differ
Hopefully someone will find this tool useful.
More information available at GitHub page. I'm planning releasing this on PyPi when it gets more mature. I will update this post when this happens. -
Elasticsearch cluster as Eucalyptus on RHEL 7.2, using Ansible
Just thought that this can be useful for someone else.
https://github.com/szborows/es-cluster-rhel7-ansible-eucalyptus -
me @ ACCU 2016 - what every C++ programmer should know about modern compilers
In Poland we have this proverb "pierwsze koty za płoty"*. Basically we say it when we do something for the first time in our lives. After finding a translation, I was quite amused - "the first pancake is always spoiled". Recently I had my debut abroad on ACCU 2016 conference. You decide if it was spoiled pancake or not :)
My short 15min talk was about modern compilers. I start with basic introduction, which may be a bit surprising, then I move to C++ standard perspective and undefined behaviors, then there's a part about optimizations and finally I'm covering the ecosystem that has grown around compilers in recent years (sanitizers, 3rd tools based on compilers, etc.). Enjoy!
Slides: with comments / without comments
GCC 6.1 released [link]
If GCC was released two weeks earlier I would definitely include one slide about how verbose and helpful compilers are nowadays.
Several years ago they were unhelpful and very quiet - even if something was going terribly wrong (and the programmer would discover this in run-time) they were happily compiling assuming that the programmer knows what she's doing.
And now.. what a change. The compilers became so friendly that GCC 6.1 can even let you know that you have unmerged git content in the file!
* direct translation doesn't work :) - "first cats over the fences". -
Really simple JSON server
As some of you may already know there's this json-server project which aims to provide an easy way to create fake servers returning JSON responses over HTTP. This is very great project, but if you need something simpler that does not necessarily follow all of the REST rules, then you're out of luck.
For instance, if you use json-server with PUT/POST requests then underlying database will change.
really-simple-json-server, on the other hand, is an effort to create really simple JSON server. To actually show you how simple it is, let's have a look at example routes (example.json).
{
"/config": {"avatar_upstream_server": "172.17.42.42"},
"/u/1/friends": ["slavko", "asia", "agata", "zbyszek", "lucyna"],
"/u/2/friends": ["adam", "grzegorz"],
"/u/3/friends": [],
"/u/4/friends": ["slavko"]
}
Then, assuming all dependencies (see below) are installed it's all about starting a server:
$ ./server.py --port 1234 example.json
And we can start querying the server!
$ curl http://localhost:1234/config
{"avatar_upstream_server": "172.17.42.42"}
The project uses Python 3.5.1 along with aiohttp package. It is shipped with Docker image, so it's pretty easy to start hacking.
$ docker build -t szborows/python351_aiohttp .
$ docker run -it -v $PWD:/app:ro szborows/python351_aiohttp /bin/bash -c "/app/server.py --port 1234 /app/example.json" -
ElasticSearch AWS cloud plugin problem connecting to Riak S3 endpoint without wildcard certs
The other day at work we were trying to use our enterprise installation of Riak S3 (open-source version of AWS S3) to store backups of some ElasticSearch instance. ElasticSearch itself is a mature project so it wasn't a surprise that there's already plugin for storing snapshots using S3 protocol. So we prepared our query and expected it to work out-of-the-box.
curl -XPUT 'http://es.address.here:9200/_snapshot/s3_dev_backup?verify=false' -d '{
"type": "s3",
"settings": {
"access_key": "*****-***-**********",
"secret_key": "****************************************",
"bucket": "elastic",
"endpoint": "s3_cloud_front.address.here"
}
}'
As usual, in corporate reality, it didn't work. Instead, we got following exception.
Error injecting constructor, com.amazonaws.AmazonClientException: Unable to execute HTTP request: hostname in certificate didn't match: <elastic.s3_cloud_front.address.here> != <s3_cloud_front.address.here> OR <s3_cloud_front.address.here>
at org.elasticsearch.repositories.s3.S3Repository.<init>(Unknown Source)
while locating org.elasticsearch.repositories.s3.S3Repository
while locating org.elasticsearch.repositories.Repository
So apparently endpoint certificate (self signed one, btw) wasn't prepared in such a way that both e.g. endpoint.address and subdomain.endpoint.address would match. In other words it wasn't wildcard certificate bound to the endpoint domain name.
We decided to debug with StackOverflow (it's common technique nowadays, isn't it :D?). After trying numerous solutions like disabling certificate check using java flags or even using so-called java agents to hijack default hostname verifier we ran out of ideas how to elegantly solve the problem. And here comes our ultimate hack - hijacking Apache httpclient library.
The idea behind the hack is simple - re-compile httpclient library with one small modification - put premature return statement at the very top of hostname verification function. The function, where the change should be made is as follows.
org.apache.http.conn.ssl.SSLSocketFactory.verifyHostname(SSLSocketFactory.java:561)
One thing to remember is that the return statement must be wrapped with some silly if statement (e.g. if (1 == 1)), so the compiler won't complain about unreachable code below. It's funny that java compiler doesn't eliminate such trivial things, but in this particular scenario it was a feature rather than a bug. If the verifyHostname method wasn't throwing an exception then the modification would be even simpler - just an return statement.
The change is trivial, so I'm not including it here. The last step is to replace httpclient jar in AWS cloud plugin with raped one and we're done. No more complains about SSL hostnames. -
Mini REST+JSON benchmark: Python 3.5.1 vs Node.js vs C++
Some time ago at Nokia I voluntarily developed a search engine tailored for internal resources (Windows shares, intranet sites, ldap directories, etc..) - NSearch. Since then few people helped me to improve it so it became unofficial "search that simply works". However, as you can image, this was purely a side-by project so I didn't pay attention to quality of the code much (I'd love to do so, but cruel time didn't permit :/). As a result during passing months a lot of technical debt was borrowed.
Recently we came to a conclusion that it's enough. We agreed that the backend of the service is going to be first in line. Because all of it was about to be rewritten we thought that maybe it's a perfect time to evaluate other technologies. Currently it's using Python2.7 + Django + Gunicorn. We consider going to either Node.js with Express 4, Python3 with aiohttp or C++. Maybe other language would be even a better match? However, we don't program in any other languages on a daily basis...
In this post I'd like to show you results of my very simple evaluation of performance of these three technologies along with some findings.
Technical facts- everything was tested on machine with Intel E5-2680 v3 CPU and 192 GBs of RAM running on RHEL-7.1 OS,
- applications were run from under Docker containers, so there might be some overhead introduced by libcontainer, libnetwork, etc.
- ab was used for benchmarking with 1M of requests with different concurrency settings
- max timeout was set to 1 second
I prepared two JSON objects used for two following benchmarks. The first was simple {"hello": "world!"} and the second was extracted directly from NSearch and connsisted of about 10k of characters, but I can't include it here. For the C++ I used Restbed framework and jsoncpp library, just to have anything with normal URL path support (otherwise results wouldn't be reliable at all).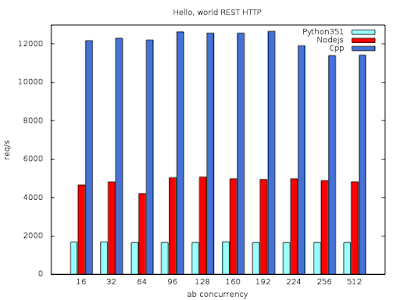

First benchmark - conclusions:- all solutions are asynchronous and event based and they're using event loops. otherwise it wouldn't be the case that 512 concurrent users can be served with max timeout set to 1 second
- starting from 192 concurrent users amount of requests per second starts to decrease slightly
- Python is more than two times slower than Node.js
- C++ is more than two times faster than Node.js
Second benchmark - conclusions:
(I excluded C++ because of convenience of filling JSON object)- the gap between Python and Node.js is much smaller when bigger JSON is in question
- apparently starting to handle a request in Python is slow, at least compared to Node.js
- replacing json.dumps with ujson.dumps increases Python performance by about 5%
- Node.js performance drops drastically when bigger JSON is used - from over 5k of requests per second to about 1700!
- Python's drop is not that drastic - from about 1700 to 1200 requests per second. It means that when the handling is ongoing, Python is not slowing down.
Why Python is so slow and Node.js much faster?
Python is interpreted language. This is main reason why it's so slow. Why it's not the case with Node.js? Because Node.js uses V8 - JavaScript interpreter - which has built-in JS JITter. JITter means Just-In-Time compiler which can speed up execution of a program by order of magnitude.
Can Python be faster? Yes!
There's also Python interpreter with built-in JITter - PyPy. Unfortunately it doesn't support 3.5.1 version of Python yet.
-
CMake disservice: project command resets CMAKE_EXE_LINKER_FLAGS
tl;dr at the bottom
CMake version: 3.3.2
I think that everyone can agree that in the world of programming there are a lot of frustrating and irritating things. Some of them are less annoying, some are more and they are appearing basically at random resulting in a waste of time. Personally I think the most depressing and worst thing that one can encounter is implicit and silent weird side effects. I was hit by such a side effect today at work and would like to write about is as well as (possibly) help future Googlers.
So let me go straight to the topic. Recently platform software that is used in one of our medium-size C++ projects has changed and started to require some additional shared library. Our project stopped to compile because this new dependency wasn't listed in link libraries. We thought that the fix will be as simple as appending one item to the list, but we were proven wrong. Apparently this new shared library was linked with several other shared objects and this complicated things a little bit.
So the linker could be potentially satisfied just with the dependency itself, but this is not what happens (at least with GNU ld). The linker tries to minimize a chance that some symbols will be unresolved in run-time, so it checks whether all of the symbols are in place, even those coming from the dependent shared object! This effectively means that the linker will go through all of the unresolved symbols in every shared object and check them, regardless whether it's needed or not. I think that this is a nice feature, but there's one caveat - the linker doesn't actually know where to look for sub-dependent shared objects. This must be explicitly specified.
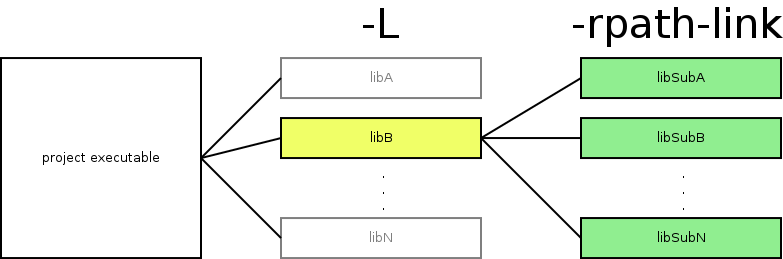
And here comes the unintuitive thing - rpath-link. Let me start with rpath, though. When the program is built and then run, the run-time linker (a.k.a loader) will look for all libraries linked to it and map them to the process memory space. There is specific order where the linker will look for the libraries: it will honor rpath in the first place, then it will consider LD_LIBRARY_PATH environment variable and finally standard system places. The rpath-link is similar to rpath, but... it's related to link-time and not run-time (this is this not intuitive part, or is it?). The linker will utilize rpath-link to look for sub-dependent libraries (Fig. 1).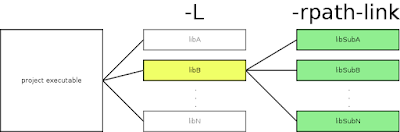 Figure. 1. Flags for project dependencies and dependencies' dependencies (sub-dependencies)
Figure. 1. Flags for project dependencies and dependencies' dependencies (sub-dependencies)
Okay, but what this all has to do with CMake?
In CMake if you want to provide linker flags you need to utilize CMAKE_*_LINKER_FLAGS family of variables. And it's working perfectly fine unless you need to provide custom toolchain and sysroot (e.g. you are doing crosscompilation). Traditional way to provide custom toolchain with CMake is to pass -DCMAKE_TOOLCHAIN_FILE to cmake command. CMake will then process the toolchain file before CMakeLists.txt allowing to change compilers, sysroots etc. It's worth mentioning here that toolchain file will be processed before project command.
As it turned out, it works flawlessly for all of the variables like CMAKE_CXX_FLAGS etc. but CMAKE_*_LINKER_FLAGS variables. It took us some time to discover that... call to project command actually resets value of the CMAKE_*_LINKER_FLAGS variables. What a pesky side effect! After some digging I've found the culprit in file Modules/CMakeCommonLanguageInclude.cmake:
# executable linker flags
set (CMAKE_EXE_LINKER_FLAGS "${CMAKE_EXE_LINKER_FLAGS_INIT}"
CACHE STRING "Flags used by the linker.")
As you can imagine CMAKE_EXE_LINKER_FLAGS_INIT is not set to anything reasonable. So the result of this is that CMake doesn't care what you had in CMAKE_*_LINKER_FLAGS. It simply drops what've been there and replaces it with empty string. In one word - disservice.
This is not end of the story, though. CMake had one more surprise for us - to our misfortune. As some of you know, there's this useful variable_watch command available in recent versions of CMake. It allows to watch variable for all reads and writes. At the beginning we were sure that something within our build system is changing our CMAKE_EXE_LINKER_FLAGS so we used variable_watch to figure out what's going on. However it didn't indicate any modification. In the end it turned out that it does not signal anything that happens under the bonnet (e.g. it ignores what project command does to observed variable). This is a joke!
Building systems like CMake is definitely not an easy task. Especially if you are targeting lots of users and support lot of scenarios ranging from compiling simple one-file project to cross-compiling huge project with huge amount of dependencies. In our case several things contributed to the final effect, but I wouldn't say that custom linker flags in a toolchain files is a corner case. I think it should be definitely fixed some day.
Or maybe this is a feature and I'm the dumb one?
tl;dr:
cmake_minimum_required(VERSION 3.0)
set(CMAKE_EXE_LINKER_FLAGS "-Wl,-rpath-link=/opt/lib64")
project(GreatProject)
# tada! CMAKE_EXE_LINKER_FLAGS is now empty. -
You know you're no-life when you do things like this during new year's eve :)

Happy 0x7e0 folks! :D -
Obvious assumptions can result in bugs in software: Flask in embedded world
So the other day our team at Nokia was requested to implement web user interface for some embedded device. Usually I write in C++, but I was excited to take this task because we were able to put Python in place. Of course it's also possible to write web applications purely in C++ (e.g. with Cheerp - I encourage you to at least read about this project), but only thin back-end was required, so going with C++ didn't seem to be good choice. After cross-compiling Python to ARM (we anticipated that knowing how to do this would be common knowledge in the Internet, but again there were few resources) it was a time to pick some framework. We decided to use Flask - small cousin of Django, because- it's smaller than Django and we were already going to eat a lot of disk space with Python itself
- it seemed like a perfect candidate for the task, because it looked so simple
I had my own goal as well :) I didn't know Flask, so there was something new to learn.
Fast forward to a place when I was about to deploy my application on the target device (after long struggle to have everything cross-compiled). Everything was set up, so I eagerly clicked the button in the front-end (react.js-based stuff) to prove that the back-end is working as well. As you can imagine - it didn't work.
http://thenextweb.com/wp-content/blogs.dir/1/files/2015/09/fn63697_01.jpg Following is what I saw in logs. Some paths were masked, just-in-case. So after looking at this I thought to myself what the... It was working on my x86 machine!
In the rest of this post I'd like to describe a reason of this failure, which I found somewhat funny.
192.168.255.*** - - [01/Jan/2004 02:00:22] "POST /************************* HTTP/1.1" 500 -
Traceback (most recent call last):
File "/****...****/Python2.7.5/lib/python2.7/site-packages/Flask-0.10.1-py2.7.egg/flask/app.py", line 1836, in __call__
return self.wsgi_app(environ, start_response)
File "/****...****/Python2.7.5/lib/python2.7/site-packages/Flask-0.10.1-py2.7.egg/flask/app.py", line 1820, in wsgi_app
response = self.make_response(self.handle_exception(e))
File "/****...****/Python2.7.5/lib/python2.7/site-packages/Flask-0.10.1-py2.7.egg/flask/app.py", line 1403, in handle_exception
reraise(exc_type, exc_value, tb)
File "/****...****/Python2.7.5/lib/python2.7/site-packages/Flask-0.10.1-py2.7.egg/flask/app.py", line 1817, in wsgi_app
response = self.full_dispatch_request()
File "/****...****/Python2.7.5/lib/python2.7/site-packages/Flask-0.10.1-py2.7.egg/flask/app.py", line 1479, in full_dispatch_request
response = self.process_response(response)
File "/****...****/Python2.7.5/lib/python2.7/site-packages/Flask-0.10.1-py2.7.egg/flask/app.py", line 1693, in process_response
self.save_session(ctx.session, response)
File "/****...****/Python2.7.5/lib/python2.7/site-packages/Flask-0.10.1-py2.7.egg/flask/app.py", line 837, in save_session
return self.session_interface.save_session(self, session, response)
File "/****...****/Python2.7.5/lib/python2.7/site-packages/Flask-0.10.1-py2.7.egg/flask/sessions.py", line 326, in save_session
val = self.get_signing_serializer(app).dumps(dict(session))
File "/****...****/Python2.7.5/lib/python2.7/site-packages/itsdangerous-0.24-py2.7.egg/itsdangerous.py", line 569, in dumps
rv = self.make_signer(salt).sign(payload)
File "/****...****/Python2.7.5/lib/python2.7/site-packages/itsdangerous-0.24-py2.7.egg/itsdangerous.py", line 412, in sign
timestamp = base64_encode(int_to_bytes(self.get_timestamp()))
File "/****...****/Python2.7.5/lib/python2.7/site-packages/itsdangerous-0.24-py2.7.egg/itsdangerous.py", line 220, in int_to_bytes
assert num >= 0
Ok, so normally I'm reading tracebacks in a bottom-up fashion. After looking at the last item in the traceback I instantly felt that something really weird is happening. Name of the file wasn't making things less weird as well. Items above the last one are not telling much more, so I had to dive in into source code to look for other hints.
Function int_to_bytes, at the very beginning, asserts that the input number is positive. Quite normal thing to do, right? So I started a debugger to check what value it got instead. I hunched that it would be -1 or something like that. Dark clouds were already in my mind at the time. I was even afraid that the hardware itself does not support some feature. That's not rare in embedded world, after all.
With the debugger I was able to retrieve value passed in. Apparently it was -220917729. Immediately I realized that I'm facing some issues with the time, and Python interpreter itself is not to be blamed. So I jumped into get_timestamp to see how the timestamp is created.
def get_timestamp(self):
"""Returns the current timestamp. This implementation returns the
seconds since 1/1/2011. The function must return an integer.
"""
return int(time.time() - EPOCH)
I double-checked that time.time() gives positive number. So after factoring out call to time() was obvious that the EPOCH is making the result negative. Then I needed to assemble two facts: EPOCH in this function is set to 1/1/2011 and the target device starts with time set to 1/1/2004. This yielded negative timestamp and a spectacular failure in result.
So I find this one funny, because apparently the authors didn't expect that the system time could be set to 2004-something :) Perhaps they assumed that it's not possible to run with a date earlier than the day when the library was published :)
Nevertheless I was expecting errors to appear in my configuration. You don't deploy web applications on embedded devices that often. Frankly speaking I encountered other funny problems during the day as well. One of them was with nginx, and if the time permits I'll write post about it as well. Stay tuned ;]
Note: I intentionally skipped description of internal Flask organization. In short words Flask uses ItsDangerous package to have signed session storage at the client-side. You can read more about it here.

slawomir.net
I'm a Linux Hooligan and this blog is about funny, interesting and weird faces of Software Engineering.