
Tests stability S09E11 (Docker, Selenium)
If you're experienced in setting up automated testing with Selenium and Docker you'll perhaps agree with me that it's not the most stable thing in the world. Actually it's far far away from any stable island - right in the middle of "the sea of instability".
When you think about failures in automated testing and how they develop when the system is growing it can resemble drugs. Seriously. When you start, occasional failures are ignored. You close your eyes and click "Retry". Innocent. But after some time it snowballs into a problem. And you find yourself with a blind fold put on but you can't remember buying it.
This post is small story how in one of small projects we started with occasional failures and ended up with... well... you'll see. Read on ;).

For past couple of months I was thinking that "others have worse setups and live", but today it all culminated, I have achieved fourth degree of density and decided to stop being quiet.
Disclaimer
In the middle of this post you might start to think that our environment is simply broken. That's damn right. The cloud in which we're running is not very stable. Sometimes it behaves like it had a sulk. There are problems with proxies too. And finally we add Docker and Selenium to the mixture. I think testimonial from one of our engineers sums it all:
if retry didn’t fix it for the 10th time, then there’s definitely something wrongAnd now something must be noted as well. The project I'm referring to is just a sideway one. It's an attempt to innovate some process, unsupported by the business whatsoever.
The triggers
I was pressing "Retry" button for another time on two of the e2e jobs and saw following.
// job 1
couldn't stat /proc/self/fd/18446744073709551615: stat /proc/self/fd/23: no such file or directory
// job 2
Service 'frontend' failed to build: readlink /proc/4304/exe: no such file or directory
What the hell is this? We have never seen this before and now apparently it became a commonplace in our CI pipeline (it was nth retry).

So this big number after /fd/ is 64-bit value of -1. Perhaps something in Selenium uses some function that returns an error and then tries to call stat syscall, passing -1 as an argument. Function return value was not checked!
The second error message is most probably related to docker. Something tries to find where is executable for some PID. Why?
"Retry" solution did not work this time. Re-deploying e2e workers also didn't help. I thought that now is the time when we should get some insights into what is actually happening and how many failures were caused by unstable environment.
Luckily we're running on GitLab, which provides reasonable API. Read on to see what I've found. I personally find it hilarious.
Insight into failures
It's extremely easy to make use of GitLab CI API (thanks GitLab guys!). I have extracted JSON objects for every job in every pipeline that was recorded in our project and started playing with the data.
The first thing that I checked was how many failures there are per particular type of test. Names are anonymized a little because I'm unsure if this is sensitive data or not. Better safe than sorry!
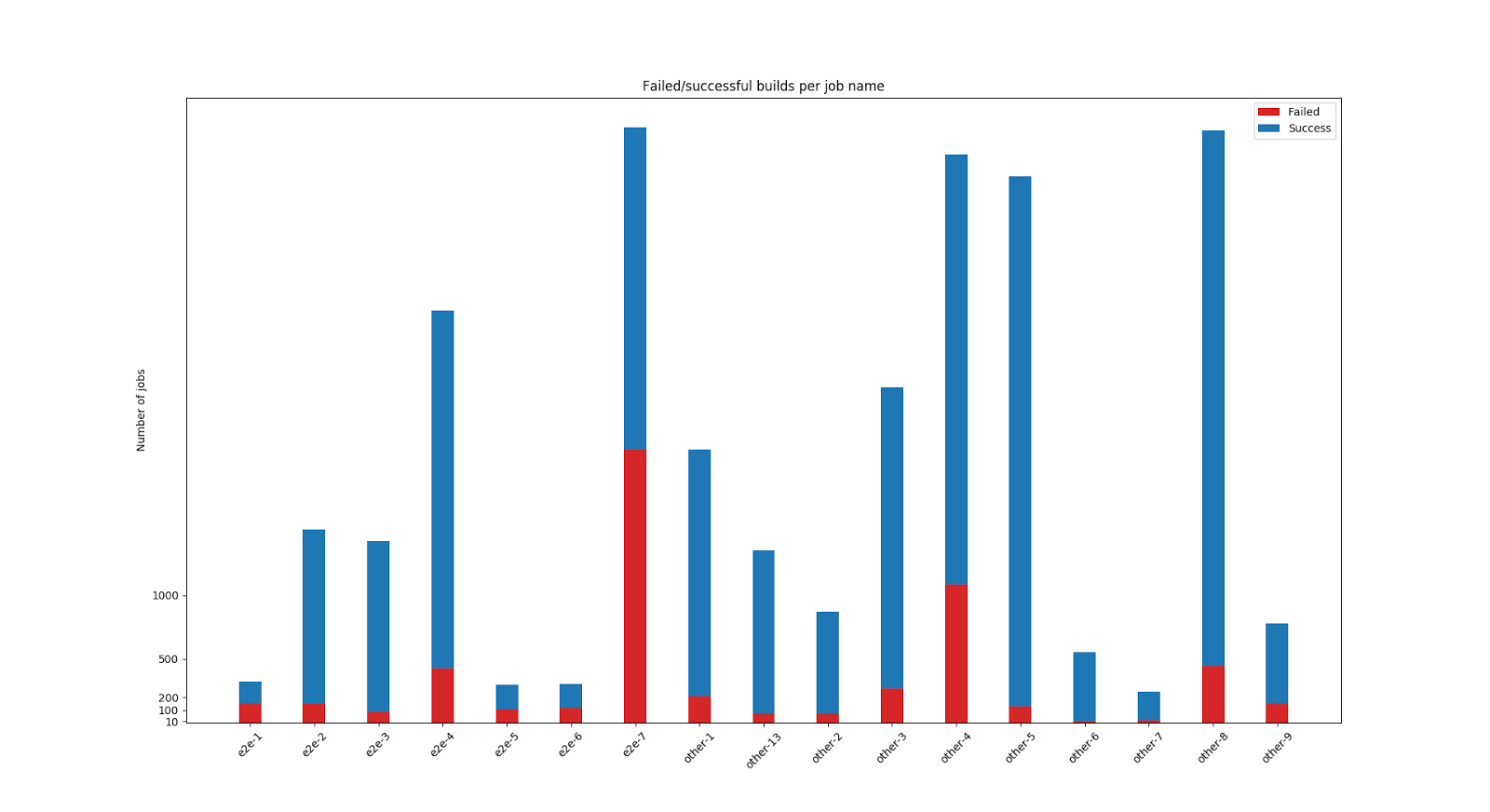 |
| Fig 1: Successful/failed jobs, per job name |
But now we can argue that maybe this is because of the bugs in the code. Let's see. In order to tell this we must analyze data basing on commit hashes: how many commits in particular jobs were executed multiple times and finished with different status. In other words: we look for the situations in which even without changes in the code the job status was varying.
The numbers for our repository are:
- number of (commit, job) pairs with at least one success: 23550
- total number of failures for these pairs: 1484
In other words, unstable environment was responsible for at least ~6.30% of observable failures. It might look like small number, but if you take into account that single job can last for 45 minutes, it becomes a lot of wasted time. Especially that failure notifications aren't always handled immediately. I also have a hunch that at some time people started to click "Retry" just to be sure the problem is not with the environment.
My top 5 picks among all of these failures are below.
hash:job | #tot | success/fail | users clicking "Retry"
----------------------------------------------------------------
d7f43f9c:e2e-7 | 19 | ( 1/17) | user-6,user-7,user-5
2fcecb7c:e2e-7 | 16 | ( 8/ 8) | user-6,user-7
2c34596f:other-1 | 14 | ( 1/13) | user-8
525203c6:other-13 | 12 | ( 1/ 8) | user-13,user-11
3457fbc5:e2e-6 | 11 | ( 2/ 9) | user-14
So, for instance - commit d7f43f9c was failing on job e2e-7 17 times and three distinct users tried to make it pass by clicking "Retry" button over and over. And finally they made it! Ridiculous, isn't it?
And speaking of time I've also checked jobs that lasted for enormous number of time. Winners are:
job:status | time (hours)
---------------------------------
other-2:failed | 167.30
other-8:canceled | 118.89
other-4:canceled | 27.19
e2e-7:success | 26.12
other-1:failed | 26.01
Perhaps these are just outliers. Histograms would give better insight. But even if outliers, they're crazy outliers.
I have also attempted to detect reason of the failure but this is more complex problem to solve. It requires to parse logs and guess which line was the first one indicating error condition. Then the second guess - about whether the problem originated from environment or the code.
Maybe such a task could be somehow handled by (in)famous machine learning. Actually there are more items that could be achieved with ML support. Two most simple examples are:
- giving estimation whether the job will fail
- also, providing reason of failure
- if the failure originated from faulty environment, what exactly was it?
- estimated time for the pipeline to finish
- auto-retry in case of env-related failure
Conclusions
Apparently I've been having much more unstable e2e test environment than I ever thought. Lesson learned is that if you get used to solve problem by retrying you loose sense in how big trouble you are.
Similarly to any other engineering problem you first need to gather data and decide what to do next. Basing on numbers I have now I'm planning to implement some ideas to make life easier.
While analyzing the data I had moments when I couldn't stop laughing to myself. But the reality is sad. It started with occasional failures and ended with continuous problem. And we weren't doing much about it. The problem was not that we were effed in the ass. The problem was that we started to arrange our place there. Insights will help us get out.
Share your ideas in comments. If we bootstrap discussion I'll do my best to share the code I have in GitHub.