
Getting all parent directories of a path
edit: reddit updates
Few minutes ago I needed to solve trivial problem of getting all parent directories of a path. It's very easy to do it imperatively, but it would simply not satisfy me. Hence, I challenged myself to do it declaratively in Python.
The problem is simple, but let me put an example on the table, so it's even easier to imagine what are we talking about.
Given some path, e.g.
/home/szborows/code/the-best-project-in-the-world
You want to have following list of parents:
/home/szborows/code
/home/szborows
/home
/
It's trivial to do this using split and then some for loop. How to make it more declarative?
Thinking more mathematically (mathematicians will perhaps cry out to heaven for vengeance after reading on, but let me at least try...) we simply want to get all of the subsets from some ordered set S that form prefix w.r.t. S. So we can simply generate pairs of numbers (1, y), representing all prefixes where y belongs to [1, len S). We can actually ignore this constant 1 and just operate on numbers.
In Python, to generate numbers starting from len(path) and going down we can simply utilize range() and [::-1] (this reverses collections, it's an idiom). Then join() can be used on splited path, but with slicing from 1 to y. That's it. And now demonstration:
>>> path = '/a/b/c/d'
>>> ['/' + '/'.join(path.split('/')[1:l]) for l in range(len(path.split('/')))[::-1] if l]
['/a/b/c', '/a/b', '/a', '/']
But what about performance? Which one will be faster - imperative or declarative approach? Intuition suggests that imperative version will win, but let's check.
On picture below you can see timeit (n=1000000) results for my machine (i5-6200U, Python 3.5.2+) for three paths:
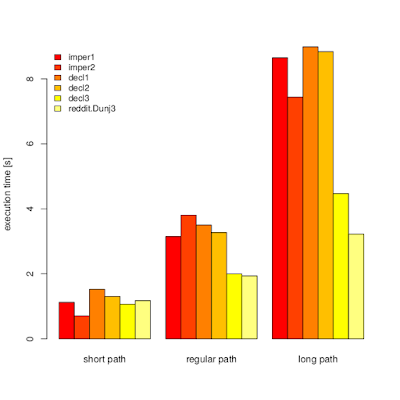 Implementations used:
Implementations used:
It started with imper1 and decl1. I noticed that imperative version is faster. I tried to speed up declarative function by replacing [::-1] with some numbers tricks. It helped, but not to the extend I anticipated. Then, I though about speeding up imper1 by using lower-level constructs. Unsurprisingly while loops and checks were faster. Let me temporarily ignore decl3 for now and play a little with CPython bytecode.
By looking at my results not everything is so obvious. decl{1,2} turned out to have decent performance with 4-part path, which looks like reasonable average.
I disassembled decl1 and decl2 to see the difference in byte code. The diff is shown below.
30 CALL_FUNCTION 1 (1 positional, 0 keyword pair) | 30 CALL_FUNCTION 1 (1 positional, 0 keyword pair)
33 CALL_FUNCTION 1 (1 positional, 0 keyword pair) | 33 CALL_FUNCTION 1 (1 positional, 0 keyword pair)
36 CALL_FUNCTION 1 (1 positional, 0 keyword pair) | 36 UNARY_NEGATIVE
39 LOAD_CONST 0 (None) | 37 LOAD_CONST 4 (1)
42 LOAD_CONST 0 (None) | 40 BINARY_ADD
45 LOAD_CONST 5 (-1) | 41 LOAD_CONST 4 (1)
48 BUILD_SLICE 3 | 44 CALL_FUNCTION 2 (2 positional, 0 keyword pair)
51 BINARY_SUBSCR
As we can see [::-1] is implemented as three loads and build slice operations. I think this could be optimized if we had special opcode like e.g. BUILD_REV_SLICE. My little-optimized decl2 is faster because one UNARY_NEGATIVE and one BINARY_ADD is less than LOAD_CONST, BUILD_SLICE and BINARY_SUBSCR. Performance gain here is pretty obvious. No matter what decl2 must be faster.
What about decl2 vs imper1?
It's more complicated and it was a little surprise that such a longer bytecode can be slower than shorter counterpart.
3 0 BUILD_LIST 0
3 STORE_FAST 1 (result)
4 6 SETUP_LOOP 91 (to 100)
9 LOAD_GLOBAL 0 (range)
12 LOAD_CONST 1 (1)
15 LOAD_GLOBAL 1 (len)
18 LOAD_FAST 0 (path)
21 LOAD_ATTR 2 (split)
24 LOAD_CONST 2 ('/')
27 CALL_FUNCTION 1 (1 positional, 0 keyword pair)
30 CALL_FUNCTION 1 (1 positional, 0 keyword pair)
33 CALL_FUNCTION 2 (2 positional, 0 keyword pair)
36 GET_ITER
>> 37 FOR_ITER 59 (to 99)
40 STORE_FAST 2 (i)
5 43 LOAD_CONST 2 ('/')
46 LOAD_ATTR 3 (join)
49 LOAD_FAST 0 (path)
52 LOAD_ATTR 2 (split)
55 LOAD_CONST 2 ('/')
58 CALL_FUNCTION 1 (1 positional, 0 keyword pair)
61 LOAD_CONST 0 (None)
64 LOAD_FAST 2 (i)
67 BUILD_SLICE 2
70 BINARY_SUBSCR
71 CALL_FUNCTION 1 (1 positional, 0 keyword pair)
74 JUMP_IF_TRUE_OR_POP 80
77 LOAD_CONST 2 ('/')
>> 80 STORE_FAST 3 (y)
6 83 LOAD_FAST 1 (result)
86 LOAD_ATTR 4 (append)
89 LOAD_FAST 3 (y)
92 CALL_FUNCTION 1 (1 positional, 0 keyword pair)
95 POP_TOP
96 JUMP_ABSOLUTE 37
>> 99 POP_BLOCK
7 >> 100 LOAD_FAST 1 (result)
103 RETURN_VALUE
The culprit was LOAD_CONST in decl{1,2} that was loading list-comprehension as a code object. Let's see how it looks, just for the record.
>>> dis.dis(decl2.__code__.co_consts[1])
21 0 BUILD_LIST 0
3 LOAD_FAST 0 (.0)
>> 6 FOR_ITER 51 (to 60)
9 STORE_FAST 1 (l)
12 LOAD_FAST 1 (l)
15 POP_JUMP_IF_FALSE 6
18 LOAD_CONST 0 ('/')
21 LOAD_CONST 0 ('/')
24 LOAD_ATTR 0 (join)
27 LOAD_DEREF 0 (path)
30 LOAD_ATTR 1 (split)
33 LOAD_CONST 0 ('/')
36 CALL_FUNCTION 1 (1 positional, 0 keyword pair)
39 LOAD_CONST 1 (1)
42 LOAD_FAST 1 (l)
45 UNARY_NEGATIVE
46 BUILD_SLICE 2
49 BINARY_SUBSCR
50 CALL_FUNCTION 1 (1 positional, 0 keyword pair)
53 BINARY_ADD
54 LIST_APPEND 2
57 JUMP_ABSOLUTE 6
>> 60 RETURN_VALUE
So this is how list comprehensions look like when converted to byte code. Nice! Now performance results make more sense. In the project I was working on my function for getting all parent paths was called in one place and perhaps contributed to less than 5% of execution time of whole application. It would not make sense to optimize this piece of code. But it was delightful journey into internals of CPython, wasn't it?
Now, let's get back to decl3. What have I done to make my declarative implementation 2x faster on average case and for right-part outliers? Well... I just reluctantly resigned from putting everything in one line and saved path.split('/') into separate variable. That's it.
So what are learnings?
Dunj3 outpaced me ;) - his implementation, which is better both w.r.t. "declarativeness" and performance:
syntax highlighting done with https://tohtml.com/python/
Few minutes ago I needed to solve trivial problem of getting all parent directories of a path. It's very easy to do it imperatively, but it would simply not satisfy me. Hence, I challenged myself to do it declaratively in Python.
The problem is simple, but let me put an example on the table, so it's even easier to imagine what are we talking about.
Given some path, e.g.
/home/szborows/code/the-best-project-in-the-world
You want to have following list of parents:
/home/szborows/code
/home/szborows
/home
/
It's trivial to do this using split and then some for loop. How to make it more declarative?
Thinking more mathematically (mathematicians will perhaps cry out to heaven for vengeance after reading on, but let me at least try...) we simply want to get all of the subsets from some ordered set S that form prefix w.r.t. S. So we can simply generate pairs of numbers (1, y), representing all prefixes where y belongs to [1, len S). We can actually ignore this constant 1 and just operate on numbers.
In Python, to generate numbers starting from len(path) and going down we can simply utilize range() and [::-1] (this reverses collections, it's an idiom). Then join() can be used on splited path, but with slicing from 1 to y. That's it. And now demonstration:
>>> path = '/a/b/c/d'
>>> ['/' + '/'.join(path.split('/')[1:l]) for l in range(len(path.split('/')))[::-1] if l]
['/a/b/c', '/a/b', '/a', '/']
But what about performance? Which one will be faster - imperative or declarative approach? Intuition suggests that imperative version will win, but let's check.
On picture below you can see timeit (n=1000000) results for my machine (i5-6200U, Python 3.5.2+) for three paths:
short_path = '/lel'
regular_path = '/jakie/jest/srednie/zagniezdzenie?'
long_path = '/z/lekka/dlugasna/sciezka/co/by/pierdzielnik/mial/troche/roboty'
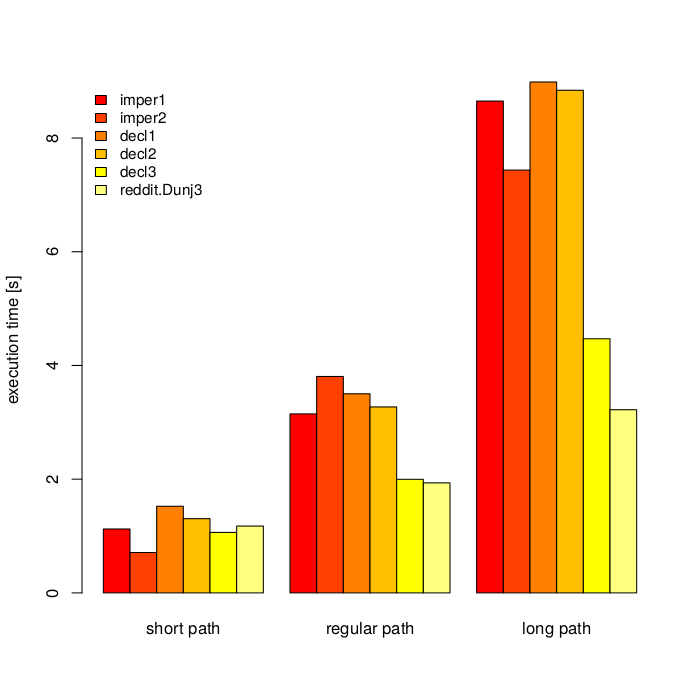
def imper1(path):
result = []
for i in range(1, len(path.split('/'))):
y = '/'.join(path.split('/')[:i]) or '/'
result.append(y)
return result
def imper2(path):
i = len(path) - 1
l = []
while i > 0:
while i != 0 and path[i] != '/':
i -= 1
l.append(path[:i] or '/')
i -= 1
return l
def decl1(path):
return ['/' + '/'.join(path.split('/')[1:l])
for l in range(len(path.split('/')))[::-1] if l]
def decl2(path):
return ['/' + '/'.join(path.split('/')[1:-l])
for l in range(-len(path.split('/'))+1, 1) if l]
# decl3 hidden. read on ;-)
It started with imper1 and decl1. I noticed that imperative version is faster. I tried to speed up declarative function by replacing [::-1] with some numbers tricks. It helped, but not to the extend I anticipated. Then, I though about speeding up imper1 by using lower-level constructs. Unsurprisingly while loops and checks were faster. Let me temporarily ignore decl3 for now and play a little with CPython bytecode.
By looking at my results not everything is so obvious. decl{1,2} turned out to have decent performance with 4-part path, which looks like reasonable average.
I disassembled decl1 and decl2 to see the difference in byte code. The diff is shown below.
30 CALL_FUNCTION 1 (1 positional, 0 keyword pair) | 30 CALL_FUNCTION 1 (1 positional, 0 keyword pair)
33 CALL_FUNCTION 1 (1 positional, 0 keyword pair) | 33 CALL_FUNCTION 1 (1 positional, 0 keyword pair)
36 CALL_FUNCTION 1 (1 positional, 0 keyword pair) | 36 UNARY_NEGATIVE
39 LOAD_CONST 0 (None) | 37 LOAD_CONST 4 (1)
42 LOAD_CONST 0 (None) | 40 BINARY_ADD
45 LOAD_CONST 5 (-1) | 41 LOAD_CONST 4 (1)
48 BUILD_SLICE 3 | 44 CALL_FUNCTION 2 (2 positional, 0 keyword pair)
51 BINARY_SUBSCR
As we can see [::-1] is implemented as three loads and build slice operations. I think this could be optimized if we had special opcode like e.g. BUILD_REV_SLICE. My little-optimized decl2 is faster because one UNARY_NEGATIVE and one BINARY_ADD is less than LOAD_CONST, BUILD_SLICE and BINARY_SUBSCR. Performance gain here is pretty obvious. No matter what decl2 must be faster.
What about decl2 vs imper1?
It's more complicated and it was a little surprise that such a longer bytecode can be slower than shorter counterpart.
3 0 BUILD_LIST 0
3 STORE_FAST 1 (result)
4 6 SETUP_LOOP 91 (to 100)
9 LOAD_GLOBAL 0 (range)
12 LOAD_CONST 1 (1)
15 LOAD_GLOBAL 1 (len)
18 LOAD_FAST 0 (path)
21 LOAD_ATTR 2 (split)
24 LOAD_CONST 2 ('/')
27 CALL_FUNCTION 1 (1 positional, 0 keyword pair)
30 CALL_FUNCTION 1 (1 positional, 0 keyword pair)
33 CALL_FUNCTION 2 (2 positional, 0 keyword pair)
36 GET_ITER
>> 37 FOR_ITER 59 (to 99)
40 STORE_FAST 2 (i)
5 43 LOAD_CONST 2 ('/')
46 LOAD_ATTR 3 (join)
49 LOAD_FAST 0 (path)
52 LOAD_ATTR 2 (split)
55 LOAD_CONST 2 ('/')
58 CALL_FUNCTION 1 (1 positional, 0 keyword pair)
61 LOAD_CONST 0 (None)
64 LOAD_FAST 2 (i)
67 BUILD_SLICE 2
70 BINARY_SUBSCR
71 CALL_FUNCTION 1 (1 positional, 0 keyword pair)
74 JUMP_IF_TRUE_OR_POP 80
77 LOAD_CONST 2 ('/')
>> 80 STORE_FAST 3 (y)
6 83 LOAD_FAST 1 (result)
86 LOAD_ATTR 4 (append)
89 LOAD_FAST 3 (y)
92 CALL_FUNCTION 1 (1 positional, 0 keyword pair)
95 POP_TOP
96 JUMP_ABSOLUTE 37
>> 99 POP_BLOCK
7 >> 100 LOAD_FAST 1 (result)
103 RETURN_VALUE
The culprit was LOAD_CONST in decl{1,2} that was loading list-comprehension as a code object. Let's see how it looks, just for the record.
>>> dis.dis(decl2.__code__.co_consts[1])
21 0 BUILD_LIST 0
3 LOAD_FAST 0 (.0)
>> 6 FOR_ITER 51 (to 60)
9 STORE_FAST 1 (l)
12 LOAD_FAST 1 (l)
15 POP_JUMP_IF_FALSE 6
18 LOAD_CONST 0 ('/')
21 LOAD_CONST 0 ('/')
24 LOAD_ATTR 0 (join)
27 LOAD_DEREF 0 (path)
30 LOAD_ATTR 1 (split)
33 LOAD_CONST 0 ('/')
36 CALL_FUNCTION 1 (1 positional, 0 keyword pair)
39 LOAD_CONST 1 (1)
42 LOAD_FAST 1 (l)
45 UNARY_NEGATIVE
46 BUILD_SLICE 2
49 BINARY_SUBSCR
50 CALL_FUNCTION 1 (1 positional, 0 keyword pair)
53 BINARY_ADD
54 LIST_APPEND 2
57 JUMP_ABSOLUTE 6
>> 60 RETURN_VALUE
So this is how list comprehensions look like when converted to byte code. Nice! Now performance results make more sense. In the project I was working on my function for getting all parent paths was called in one place and perhaps contributed to less than 5% of execution time of whole application. It would not make sense to optimize this piece of code. But it was delightful journey into internals of CPython, wasn't it?
Now, let's get back to decl3. What have I done to make my declarative implementation 2x faster on average case and for right-part outliers? Well... I just reluctantly resigned from putting everything in one line and saved path.split('/') into separate variable. That's it.
So what are learnings?
- declarative method turned out to be faster than hand-crafter imperative one employing low-level constructs.
Why? Good question! Maybe because bytecode generator knows how to produce optimized code when it encounters list comprehension? But I have written no CPython code, so it's only my speculation. - trying to put everything in one line can hurt - in described case split() function was major performance dragger
Dunj3 outpaced me ;) - his implementation, which is better both w.r.t. "declarativeness" and performance:
list(itertools.accumulate(path.split('/'), curry(os.sep.join)))
syntax highlighting done with https://tohtml.com/python/