-
Heirloom on journal cover

Couple of months ago I wrote an article to “Programista” journal (a Polish one) about how DEFLATE algorithm works under the bonnet. Apart from describing DEFLATE it illustrates clever use of a indexed_gzip to decompress random part of gzipped file without decompressing what’s before. I got it to cover and thought it’s a good chance to put some hidden information over there. I decided to put heirloom for my children. I wonder what will be their reaction when they’re in their 20’s and somebody tells them :)
-
Automating full-page web screenshots without ads and other crap
Have you ever hit a wall with your idea/project? I recall that the other day I heard following words about my project.
we won’t invest, because we aren’t sure if that boat will become a ship in a future
Cruel words, right? Well. Later on it emerged that they were right with their judgement. Not every boat becomes a ship. Just few do. One of the most exceptional example is the Internet. It was a boat and it became a ship. Comparing it a ship is actually not fair, but you get it.
When the boat becomes a ship it can accommodate much more people, it requires more power to operate, it looks much better, it is more robust, it’s more powerful and offers more services, it’s less maneuverable etc. All of this is true for the Internet too. Target audience is much broader and therefore the goals become different. Revenue streams are different too. Last but not least, technologies and solutions from the past are not suitable anymore and that can create new technical challenges for people that work with them.
In this post I want to describe how and why I automated taking full-page screenshots of web pages without advertisments, GDRP notifications, Cookie/privacy alerts etc. Back then it was pretty easy thing to do. That, unfortunately, doesn’t hold anymore.
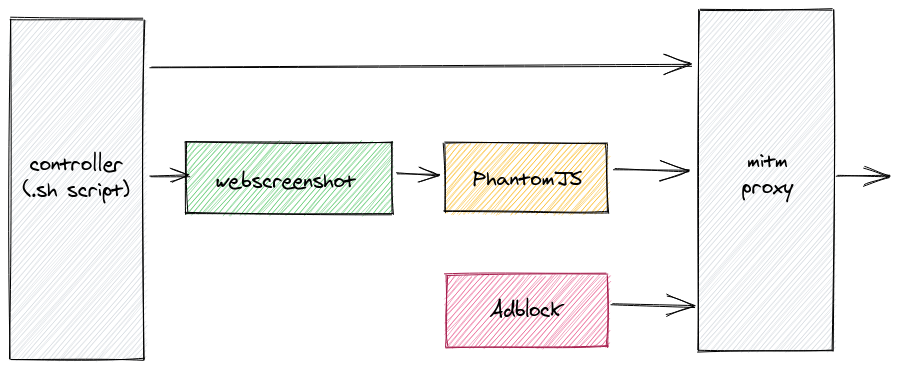
-
babla: command line translation tool (Polish-English)
This is gonna be pretty short. Some time ago I created small script that uses bab.la web service to translate words between Polish and English. Some people from my team are already using it and found it to be convenient.
$ pip3 install babla $ babla sumienny conscientious dutiful assiduous faithful -
Automating vimdiff's HTML diff (TOhtml)
Proof of concepts are often done pretty differently than other kind of work. The rules described in (in)famous “Effective engineer” are even more important to succeed with PoCs. At the end of a day it all gravitates around “value added divided by effort spent”.
I was doing some quick PoC project that lets user paste log fragment and see what are other log fragments in the database that are most similar to the pasted one. But apart from showing the list user wants to inspect the differences too.
Simplest solution is to generate diff in e.g. HTML and present it to the user. But what is the best way to achieve that quickly? By using existing tool!
This post is about automating
vimdiff’sTOhtmlusingheadlessvimlibrary. Apart from presenting actual solution I cover some of the details on how Vim loads configuration files, how can we pass commands to it, etc.
-
Accessing globals after wrong code.interact() call
def foo(): global database_index bar() import code; code.interact(local=locals())Have you ever called
code.interact()and forgot to passlocal=locals()orlocal={**globals(), **locals()}. Most of the time you may just exit interactive console, add missing parameters and run program again. But what if the program was executing for couple of hours before interactive console was started? You might want to access e.g. global variables without running it again. Fortunately Python is a language for adults, so it’s totally doable. -
tee equivalent as a Python class
Do you know
teeprogram? Itsmanpage reads:tee - read from standard input and write to standard output and files
It makes it easy to split output of one program into both stdout and files. It’s a nice UNIX tool. Recently I was doing code review and it turned out that equivalent of such thing may be pretty useful in Python programs too:
with open("file1.txt") as f1, tee(open("file2.txt")) as f2: shutil.copyfileobj(f1, f2) if f2.tail not in ('\r', '\n'): f2.fileobj.write('\n')It allows to do extra work, so we can employ it to e.g. simultaneous hash calculation or other job.
-
Roccat Suora driver for Linux > 4.11.0
Recently I decided it’s time to install dedicated driver for my keyboard to programatically control its LED behavior. I have Roccat Suora keyboard. Fortunately all of the code is already available here. However the kernel module failed to compile because of
signal_pendingbeing undeclared. I had to add following code inhid-roccat.cand it worked like a charm.#include <linux/version.h> #if (LINUX_VERSION_CODE >= KERNEL_VERSION(4, 11, 0)) #include <linux/sched/signal.h> #endifsignal_pendingwas moved tolinux/sched/signal.h -
Explanation of C++ expression on Code::Dive T-Shirts
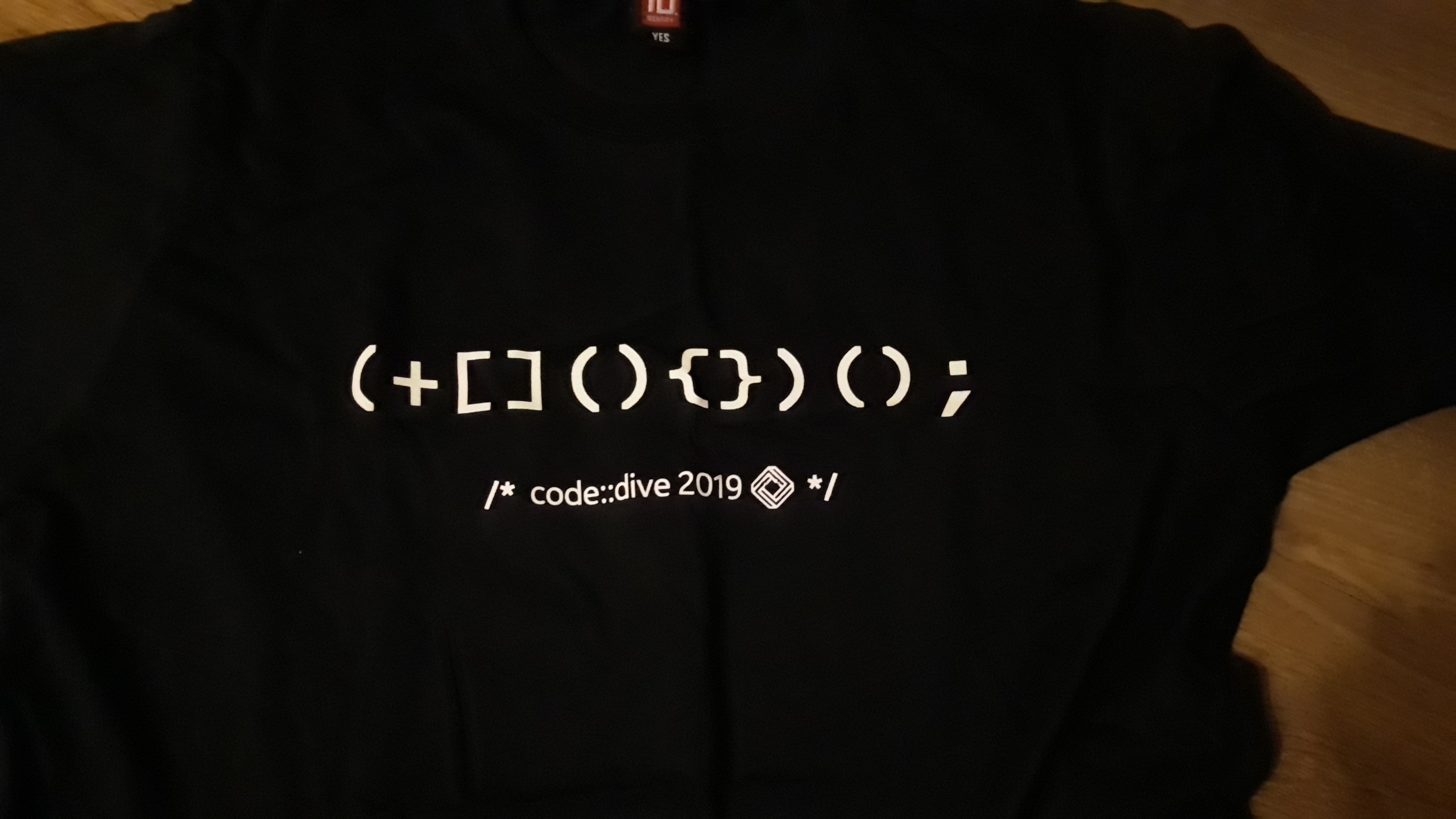
-
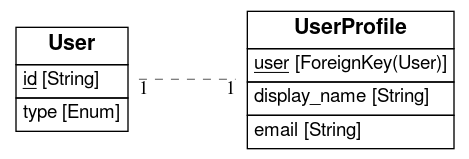
savis - visualize SQLAlchemy models without fuss
-
GarageTalks: Taming Kubernetes jobs with Python
Recently Nokia launched fancy new Garage Talks meetup. It gravitates around cloud technologies, development tools, architecture etc. I had a talk last time and it was about Kubernetes jobs and how you can create and controll them using official python client. Slides can be found here.
-
HexIT Escape Room for IT geeks - escape if you can (Wrocław, Poland)
 I'm glad to announce that we have launched an escape room that targets IT people (developers, testers etc). So far it works well for one month and about 30 teams (3-4 people) have already enjoyed it.
I'm glad to announce that we have launched an escape room that targets IT people (developers, testers etc). So far it works well for one month and about 30 teams (3-4 people) have already enjoyed it.
Please yourself and pay us a visit! Basing on the reactions of other teams I can guarantee remarkable experience. You don't need to be a "hackerman" to complete the room, but if you are you will do so faster ;-). Teams can be mixed too (but at least one person with basic programming skills is rather required).
Room location & partnership with Let Me Out.
ul. Bernardyńska 4 (close to Galeria Dominikańska), IInd floor (map below)
Link to Google Maps
Book here: letmeout.pl (select Wrocław)
I'm the author and creator of the room but I'm not running the business. The company that operates the room is Let Me Out and has excellent portfolio of other escape rooms in lot of Polish cities and Brussels.
Room theme
It goes like this:
Another country is trying to become an atomic superpower through the development of nuclear weapons, which consequently results in the destabilization of the region and the escalation of the international conflict on an unprecedented scale. The world is on the verge of the outbreak of World War III. The only salvation is to infect the secret plantation of uranium treatment with a computer virus. Will a group of programmers be able to prevent nuclear war in 90 minutes?
I received some suggestions that the room itself should be marketed as "an ordinary escape room with extra IT riddles". And this is actually what I wanted to build. Not to give a desk, PC and Jira for the players, but give them a nice mix of good background story with many different IT riddles.
Solve the riddles while saving the world! :-)
Easter Egg
In the room there are some easter eggs. One of them will let you listen to some famous song. The code is what comes out of `1900 + 80 + 9` and you need to properly enter it. You'll know where once you're there ;)
Room name
Funny fact about the name: it incorporates four things:- Hex, as a reference to hexadecimal numbers (you'll see some of them ;-)
- Hex, as a uranium industry jargon name for Uranium Hexafluoride
- Exit, related to Escape word
- IT - information technology
-
Global app variables in connexion & aiohttp
tl;dr: use pass_context_arg_name and api.subapp
Nowadays microservice architecture seem to be the default way distributed applications are build. Also, people started to treat APIs as a first-class citizen. Hence, it's no surprise that projects like Swagger/OpenAPI are gaining popularity on a daily basis.
One of Python OpenAPI implementations that I discovered recently is Connexion. Advantages of using OpenAPI are obvious: e.g. you can decouple endpoints schema from app logic and have only single place where whole API is described. Even the fact that there's Swagger UI for API users can be quite beneficial.
In the past I've been looking at different frameworks like django-rest, but nothing seemed as simple as Connexion. I decided to play it with right after discovering that the guys from Zalando added support for aiohttp (asynchronous HTTP server) - the framework we use extensively in our projects.
So what's the problem? What this post is about? Although Connexion is great, it is undocumented (or my DuckDuckGo-foo sucks and this is in fact just not well-documented) how to glue it with how global variables are handled in aiohttp - using app as an container for globals. Consider following snippet:
async def handler(request):
# this is how aiohttp creators recommend to access global variables
# e.g. database handle
request.app['redis_con'].incr('visits')
return web.Response(body=b'hello')
Nothing much more than ordinary aiohttp handler that uses redis_con global. Unfortunately using globals with Connexion is not that straightforward. Example how Connexion handlers look like (following comes from Connextion docs):
def example(name: str) -> str:
return 'Hello {name}'.format(name=name)
There's no request parameter! It took me some time to find out how to let Connexion pass request (aiohttp context) to handlers. I had to dig into source code to figure out following:
def start(redis_con):
app = connexion.AioHttpApp(__name__, specification_dir='swagger/')
api = app.add_api('api.yml', pass_context_arg_name='request')
api.subapp['redis_con'] = redis_con
app.run()
We're passing pass_context_arg_name parameter and it turns out that for aiohttp the context is the request. The unintuive thing is that subapp part. We need to use it in order to set global. This part I have found in aiohttp_jinja2.setup function. Now, we can use it in handlers like following.
async def handler(*args, **kwargs):
kwargs['request'].app['redis_con'].incr('visits')
return web.Response(body=b'hello')
That's all. Seems like easy thing, but nowhere online could I find it. -
Handling multiple identical USB ethernet adapters (Raspberry PI, udev)
You have to build simple ethernet-connected chain of devices and continuously check that it's healthy. In order to save money and time you decide to replace individual devices (say Raspberries) with multiple USB ethernet adapters. You buy Chinese ones. What could go wrong?
We're building an escape room. There's plenty of them in Wrocław but our is special, because it's dedicated for IT guys. Random people would have lot of trouble solving even first riddles. These riddles are supposed to be great fun for tech people.
I don't want to spoil what are the riddles. Let us stay with the technical problem that I had at hand. Multiple devices need to be accessible in some specific configuration to solve one of the riddles. It made no sense to have these devices if their only purpose was to respond to some ICMP packet (certainly there is even more low-level solution, but we need something easy and reliable now). We decided to limit number of these and to attach USB ethernet adapters to each. My colleague has bought some Chinese adapters like on picture below and problems emerged immediately.
BTW the funny fact about CE marks on some devices (I'm not sure about this one) may not actually be CE marks but "China Export". You can read more about it here.
Perfect hardware clones!
So what's the problem? Well... when I firstly plugged in first adapted I made some configuration changes in Raspbian and was happy that everything works flawlessly. However, couple of days after I connected second adapter to the same device and it was the time when the problem surfaced. All of these USB adapters had the same MAC address. To make it even worse, after inspecting what's in /sys, I was sure that all of the USB parameters are also identical. In other words these devices were perfect clones. ROM was the same for all of them! And btw one out of 8 was not working at all.
Why this is a problem? It's because if the names are the same, kernel will rename network interface name to something like rename{number} and there's no reliable way to tell which interface is connected to which cable. Sadly, they also share the same MAC, so if you connect all adapters to the same switch, funny things will start to happen!
Ubootdev for the rescue
I'm not that into Linux, but I immediately knew where to look for - udev. I was afraid that there won't be a way to differentiate between adapters at udev level and I was right.
However, some silly (maybe not silly. If something is silly but it works it means it's not silly ;-) solution is possible: differentiate USB ports rather than the devices themselves.
I started to read documentation and have found that you can create rules based on ports, like following:
SUBSYSTEM=="net", KERNELS=="1-2:1.0", ATTR{address}=="00:e0:4c:53:44:58"
net is the subsystem we want. USB port must be provided in KERNELS parameter (S at the end is both intentional and crucial). By providing address attribute you may further target only these Chinese adapters you have on the desk.
Finding out usb ports proved to be a little tricky task. You can do it using udevadm utility.
I have prepared diagram for my RPi 3:
Please take note that this may be different in your case. The reason is that it all depends on:- hardware revision
- firmware versions
- kernel version
- kernel modules version
- you can target using ATTR{address}=="mac-here", but apparently there's no way to change it (ATTR{address}="new-mac" doesn't work)
- changing MAC address is still possible (e.g. ifconfig <ifname> hw ether ...) and you can even use the name you set, but you must use absolute paths to executable!
SUBSYSTEM=="net", KERNELS=="1-1.2:1.0", ATTR{address}=="00:e0:4c:53:44:58", NAME="kabelek1", RUN+="/sbin/ifconfig kabelek1 hw ether 00:e0:4c:00:00:01"
SUBSYSTEM=="net", KERNELS=="1-1.4:1.0", ATTR{address}=="00:e0:4c:53:44:58", NAME="kabelek2", RUN+="/sbin/ifconfig kabelek2 hw ether 00:e0:4c:00:00:02"
SUBSYSTEM=="net", KERNELS=="1-1.3:1.0", ATTR{address}=="00:e0:4c:53:44:58", NAME="kabelek3", RUN+="/sbin/ifconfig kabelek3 hw ether 00:e0:4c:00:00:03"
SUBSYSTEM=="net", KERNELS=="1-1.5:1.0", ATTR{address}=="00:e0:4c:53:44:58", NAME="kabelek4", RUN+="/sbin/ifconfig kabelek4 hw ether 00:e0:4c:00:00:04"
And voile-a! You are free to connect lot of adapters to single Raspberry. You still need to maintain USB-port and Ethernet cables coupling and also you will need to do something with the cables ;)
This is how my desk looked like when I was figuring things out.To summarize, almost everything can be done and if something really can't, then you somehow can circumvent. However I believe this trick is just palliative. Chinese adapters can backfire any time, so if you require reliability, then you should look for other hardware.
-
Preconfigured Jenkins cluster in Docker Swarm (proxy, accounts, plugins)
In recent years lot of popular technologies were adjusted so they can run in Docker containers. Our industry even coined new verb - dockerization. When something is dockerized we usually expect it to behave like self-contained app that is controlled with either command line switches or environment variables. We also assume that apart of this kind of customization the dockerized thing is zero-conf - it will start right away with no further magic spells.
It's just awesome when things work that way. Unfortunately there are exceptions and Jenkins is one of them. The problem with Jenkins is that even when you start it from within a container, you still need to:- open configuration wizard (it's a web page)
- prove that you're the guy: pass it's challenge by reading some magic file and pasting its content into configuration wizard
- configure proxy, if you're behind one
- select plugins to be installed during initialization
- setup admin account
 So this post, in DuckDuckGo-friendly list, explains how to:
So this post, in DuckDuckGo-friendly list, explains how to:- pre-configure Jenkins with custom user (admin) account
- pre-configure Jenkins with a proxy
- pre-configure Jenkins with specified plugins
- run Jenkins master and slaves entirely in Docker Swarm with Jenkins' own Swarm plugin for automatic master-slave connection establishment
- allow Jenkins jobs to execute other Docker containers nearby (the daemon's sock trick)
http://www.rustypants.net/wp-content/uploads/2008/10/satanspbeach.jpgAbandon all hope, ye who enter here.
I remember that in one of C projects (not sure what was it, but perhaps something from GNU, maybe RMSupdate: it was xterm) there was this comment "abandon all hope, ye who enter here".It also mentioned how many people have ignored this warning and tried to refactor something.I have the same reflections w.r.t. configuring Jenkins without custom Groovy scripts. I was reluctant to learn new language, but eventually this seemed like the most reasonable way to continue.
Of course, all of following problems can be solved in a troglodyte way too. E.g. you can configure by hand, extract Jenkins home directory, targz it and re-use. But that brings couple of other problems. Also, surprisingly fresh Jenkins home weighted about 70MBs in my case. I always thought that it's just bunch of XML files, but perhaps it's not that straightforward. Since primitive solutions didn't work right away, I decided to stop for a while and try to solve the problem "the right way".System overview & requirements.
System is simple: there's one master (and it's an brilliant example of a SPOF, but nobody cares, since you're unsure of future) and number of workers (slaves). We want workers to register to the master automatically. Unfortunately this is not possible using plain JNLP solution, because you need to register the worker in master prior to establishing a link. In theory you could do some curl magic, but fortunately there's a plugin that does it for you - Jenkins Swarm (not to be confused with Docker Swarm, as it has literally nothing to do with it). Jenkins Swarm plugin consists of two things: a plugin for master Jenkins and Java JAR for slaves.
So we're set up. Jenkins Swarm will take care of auto-connecting slaves. Now, we must run dockerized version of these slaves and put it to Docker Swarm. But before we talk about slaves, let's handle the master.Jenkins master with plugins, proxy, and extra configuration.
Let me paste Dockerfile and explain it line by line.
FROM jenkins/jenkins:2.89.1-alpine
ARG proxy
ENV http_proxy=$proxy https_proxy=$proxy
USER root
RUN apk update && apk add python3
COPY requirements.txt /tmp/requirements.txt
RUN pip3 install -r /tmp/requirements.txt
USER jenkins
COPY plugins.txt /plugins.txt
RUN /usr/local/bin/install-plugins.sh swarm:3.6 workflow-aggregator:2.5
ENV JAVA_OPTS="-Djenkins.install.runSetupWizard=false"
COPY security.groovy /usr/share/jenkins/ref/init.groovy.d/security.groovy
COPY proxy.groovy /usr/share/jenkins/ref/init.groovy.d/proxy.groovy
COPY executors.groovy /usr/share/jenkins/ref/init.groovy.d/executors.groovy
We must start with some Jenkins image in order to customize it. In my case that's slim Alpine Linux version 2.89.1. Then there's build argument for the proxy. You can ignore this part if you're not behind one.
Before we modify the image, we need to switch to root user. After we're done we should switch it back to jenkins fo better security (if you wonder how to check it without base image Dockerfile, docker history command is your friend). In my case I'm also installing some python3 stuff defined in requirements.txt dependency file. If you're not willing to add any package to the system, you can skip this entire part too.
Then, we approach configuring plugins. In different places in Internet you can find an advice to use /usr/local/bin/plugins.sh but believe me you don't want to do this, as this installs plugins without their dependencies. Newer install-plugins.sh script takes care of dependencies for you. In our case we're installing two plugins. You might want to install just the essential one - the swarm plugin.
Now, four nonstandard lines. I believe that setting runSetupWizard to false is self-explanatory. The rest of lines are there for account setup, proxy configuration and executors configuration.
Let's start with setting up admin account. Groovy here we go!
#!groovy
import jenkins.model.*
import hudson.security.*
import jenkins.security.s2m.AdminWhitelistRule
def instance = Jenkins.getInstance()
def user = new File("/run/secrets/jenkinsUser").text.trim()
def pass = new File("/run/secrets/jenkinsPassword").text.trim()
def hudsonRealm = new HudsonPrivateSecurityRealm(false)
hudsonRealm.createAccount(user, pass)
instance.setSecurityRealm(hudsonRealm)
def strategy = new FullControlOnceLoggedInAuthorizationStrategy()
instance.setAuthorizationStrategy(strategy)
instance.save()
Jenkins.instance.getInjector().getInstance(AdminWhitelistRule.class).setMasterKillSwitch(false)
I'm not Groovy expert so don't judge me by the code above. I have started with just knowledge that it runs over JVM :). It's actually looks like nice managed language. The good part is that, as in Python, the code mostly speaks for itself. Hudson Legacy is visible here as well. I won't go into details - if you want to know from where all of this magic comes, pay a visit to official docs. Don't forget that you can also use infamous Jenkins console. I found Groovy's dump built-in very helpful too.
So the above script will actually setup an admin account, but doesn't hardwire anything. Both username and password come from Docker Secrets that allows you to manage sensitive data in your Swarm cluster nicely.
Now, the second script is for proxy:
#!groovy
import jenkins.model.*
import hudson.*
def instance = Jenkins.getInstance()
def pc = new hudson.ProxyConfiguration("1.2.3.4", 8080, null, null, "localhost,*.your.intranet.com");
instance.proxy = pc;
instance.save()
Here's some magic too. It sets up proxy 1.2.3.4:8080 but with specified exceptions. Then it modifies Jenkins instance (which seem to be a singleton).
And finally, executors part. I wanted this one so master is not used as a worker at all.
import jenkins.model.*
Jenkins.instance.setNumExecutors(0)Slaves.
Now, since the master is ready, let's configure slaves. Their Dockerfile is as follows.
FROM docker:17.03-rc
ARG proxy
ENV https_proxy=$proxy http_proxy=$proxy no_proxy="localhost,*.your.intranet.com"
RUN apk --update add openjdk8-jre git python3
RUN wget -O swarm-client.jar http://repo.jenkins-ci.org/releases/org/jenkins-ci/plugins/swarm-client/3.3/swarm-client-3.3.jar
ENV http_proxy= https_proxy=
COPY entrypoint.sh /
RUN chmod +x /entrypoint.sh
CMD ["/entrypoint.sh"]
This time base image is docker, because we want to have docker installed within this docker container (so this container can spawn other containers). After setting proxies (the part that is not mandatory) we must download Java Runtime Environment version 8 and download swarm-client JAR. I'm using version 3.3 which is accessible through URL as for today.
Finally, there's an entrypoint that will execute swarm-client and do all the magic, but it heavily relies on Docker Secret named jenkinsSwarm, which should look like following.
-master http://master_address:8080 -password jenkinsUser -username jenkinsPassword
Here master_address must be known to slave machines (e.g. in /etc/hosts, Consul or something). You should also include username and password - the same ones that you share in other Docker Swarm secrets.
If you're using Ansible like I do, it's pretty straightforward to utilize variables instead not to hardcode credentials. For instance ansible-vault can be used for this.
entrypoint.sh itself is almost one-liner:
mkdir /tmp/jenkins
java -jar swarm-client.jar -labels=docker -executors=1 -fsroot=/tmp/jenkins -name=docker-$(hostname) $(cat /run/secrets/jenkinsSwarm)
It assumes that it's running in the Swarm and can access /run/secrets/jenkinsSwarm (the line that's pasted above).Glueing it all together.
Building blocks are already in place. Now it's time to glue everything together. I don't want to go into details here, because this is not primary topic of this blog post. If you're interested in how personally I did everything please let me know in comments, so I will create GitHub repo. Let me however give you some important hints:- if you want slave to be able to spawn other containers (on the same host on which the slave is running), you must bind mount docker.sock file, e.g. like this: "/var/run/docker.sock:/var/run/docker.sock". There's more to this, though! Docker daemon will not allow jenkins user to spawn containers, so you must somehow circumvent this problem. I'm circumventing this by adding jenkins user to docker group, but this works only because there's 1:1 mapping between the host and container.
- you should have three secrets in Docker Swarm cluster: jenkinsUser, jenkinsPassword and jenkinsSwarm with username, password, and swarm-client.jar arguments respectively
- machines must be able to communicate. For internal JNLP communication, port 50000/tcp must be opened.
- if you set deployment mode to global in docker-compose.yml file (if you're using one), then you will have as much slaves as machines in the cluster, which can be nice
- if you're gonna stick to this solution for a longer period of time I recommend to think about horizontally scaling out and in: it should be as simple as adding/removing machines from the cluster: just one terraform command followed by ansible-playbook spell.
Hopefully this post helps you with setting up Jenkins cluster that simply works. If you'd like to see the code, let me know in comments! -
Airflow Docker with Xcom push and pull
Recently, in one projects I'm working on, we started to research technologies that can be used to design and execute data processing flows. Amount of data to be processed is counted in terabytes, hence we were aiming at solutions that can be deployed in the cloud. Solutions from Apache umbrella like Hadoop, Spark, or Flink were at the table from the very beginning, but we also looked at others like Luigi or Airflow, because our use case was neither MapReducable nor stream-based.
Airflow caught our attention and we decided to give it a shot just to see if we can create PoC using it*. In order to execute PoC faster rather than slower, we planned to provision Swarm cluster for this.
In the Airflow you can find couple of so-called operators that allow you to execute actions. There are operators for Bash or Python, but you can also find something for e.g. Hive. Fortunately there is also Docker operator for us.
Local PoC
PoC started on my laptop and not in the cluster. Thankfully, DockerOperator allows you to pass URL to docker daemon, so moving from laptop to cluster is close to just changing one parameter. Nice!
If you want to run Airflow server locally from inside container, and have it running as non-root (you should!) and you bind docker.sock from host to the container, you must create docker group in the container that mirrors docker group on your host and then add e.g. airflow user to this group. That does the trick...
So just running DockerOperator is not black magic. However, if your containers need to exchange data it starts to be a little bit more tricky.
Xcom push/pull
The push part is simple and documented. Just set xcom_push parameter to True and last line of container stdout will be published by Airflow as it was pushed programatically. It looks that this is natural Airflow way.
Pull is not that obvious. Perhaps because it's not documented. You can't read stdin or something. The way to do this involves joining two dots:- command parameter can be Jinja2-templated
- one of the macros allows you to do xcom_pull
FROM debian
ENTRYPOINT echo '{"i_am_pushing": "json"}'
Simple enough. Now pulling container:
FROM debian
COPY ./entrypoint /
ENTRYPOINT ["/entrypoint"]
Entrypoint script can be whatever and will get the JSON as $1. Crucial (and also easy to miss) thing that is required for it to work is that ENTRYPOINT must use exec form. Yes, there are two forms of ENTRYPOINT. If you use the one without array, then parameters will not be passed to the container!
Finally, you can glue things together and you're done. The ti macro allows us to get data pushed by other task. ti stands for task_instance.
dag = DAG('docker', default_args=default_args, schedule_interval=timedelta(1))
t1 = DockerOperator(task_id='docker_1', dag=dag, image='docker_1', xcom_push=True)
t2 = DockerOperator(task_id='docker_2', dag=dag, image='docker_2', command='{{ ti.xcom_pull(task_ids="docker_1") }}')
t2.set_upstream(t1)
Conclusion
Docker can be used in Airflow along with Xcom push/pull functionality. It isn't very convenient and is not well documented I would say, but at least it works.
If time permits I'm going to create PR for documenting pull op. I don't know how it works out, because in Airflow GH project there are 237 PRs now and some of them are there since May 2016!
* the funny thing is that we considered Jenkins too! ;-)

slawomir.net
I'm a Linux Hooligan and this blog is about funny, interesting and weird faces of Software Engineering.






