
Automating full-page web screenshots without ads and other crap
Have you ever hit a wall with your idea/project? I recall that the other day I heard following words about my project.
we won’t invest, because we aren’t sure if that boat will become a ship in a future
Cruel words, right? Well. Later on it emerged that they were right with their judgement. Not every boat becomes a ship. Just few do. One of the most exceptional example is the Internet. It was a boat and it became a ship. Comparing it a ship is actually not fair, but you get it.
When the boat becomes a ship it can accommodate much more people, it requires more power to operate, it looks much better, it is more robust, it’s more powerful and offers more services, it’s less maneuverable etc. All of this is true for the Internet too. Target audience is much broader and therefore the goals become different. Revenue streams are different too. Last but not least, technologies and solutions from the past are not suitable anymore and that can create new technical challenges for people that work with them.
In this post I want to describe how and why I automated taking full-page screenshots of web pages without advertisments, GDRP notifications, Cookie/privacy alerts etc. Back then it was pretty easy thing to do. That, unfortunately, doesn’t hold anymore.
Information in the Internet was always ephemeral. What if you find some information on some web page and store URL for future? You may go back after a while to discover it’s already gone (404). It may have been moved somewhere else, or maybe it’s not available anymore. Yes, you can use search engine to find another source of information about the topic, but only if the URL contains some key words, or you were precautious enough to copy page title apart from the URL. I created small system to make full-page screenshots of pages to circumvent this whole problem.
In the past you could simply use curl to create your own copy of a page, but unfortunately nowadays it
is not that straighforward:
- lot of pages require JavaScript, and significant part of them require JavaScript to load the content
- some pages are protected (e.g. against DDoS) and will check the browser
- there is a lot of bloat (GDRP, Cookie and privacy policies, full-page advertisments)
- pages are resource-heavy
- pages require lot of content that come from 3rd-party services (CDNs etc)
You can use service like archive.is, but for the sake of the article I’m gonna assume you want your own local copy. There are many ways how we can make a copy of a website, but I’m going to focus on the most primitive one: full-page screenshots. I find screenshots easy to preview and easy to share.
So what are challenges of automating web page screenshots?
- in order for everything to work right we need underlying browser to render the page for us
- we need to take full-page screenshot, so simple screen grabbing won’t work
- page contents are gathered asynchronously, so we need to somehow instrument the browser to take screenshot only after page is fully loaded
- we need to hide all GDRP, TOS, Cookie windows before taking a screenshot
- since we want automated solution, we look for headless solution (no rinning X’es)
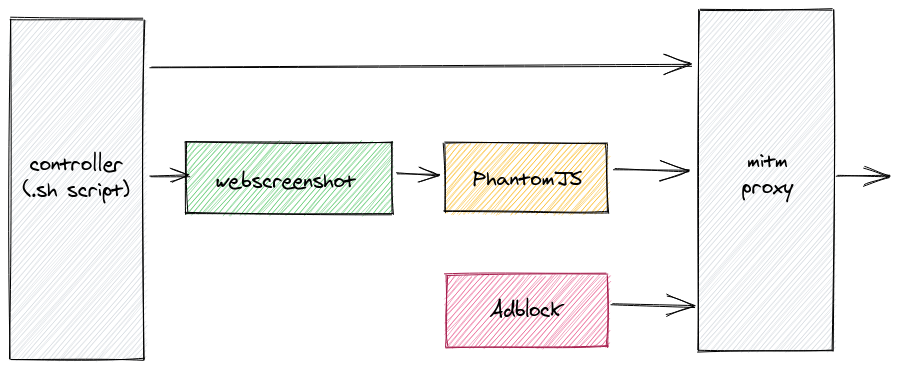
Points 1, 2, 3 and 5 are solved by using headless automated browser like PhantomJS. We will use webscreenshot Python package as a wrapper. It contains convenient script to take full-page screenshot.
To solve point 4, we will use mitm-adblock that uses mitmproxy under the bonnet. Basically it forms a HTTP(S) proxy that will reject JavaScript scripts according to Adblock rules. These are the same rules that are used by browser extensions like Adblock, uBlock etc.
Picture above illustrates how the system works. After cloning mitm-adblock we cd into its
directory. When running for the first time, we should execute update-blocklists to update Adblock
rules. Then we execute go script in background (or foreground in another terminal).
Second step is to pull webscreenshot and cd into its directory. Assuming that list of URLs is
prepared and available in file /tmp/links.txt we do following:
for link in $(cat /tmp/links.txt); do python3 webscreenshot.py -P 'http://localhost:8118' "$link"; done
Where localhost:8118 is endpoint of our mitmproxy. Depending on how many links we have, it may
take some time. When it finishes we should have all of our screenshots available in screenshots
subdirectory.
And that’s all!
Caveats and further steps
Described solution is definitely not complete, but it was enough for my pet project. Problems that I’ve encountered include:
- some pages require logging in. This could be solved in numerous ways: e.g. hooking in into
webscreenshot.js, custom logic inmitmproxy, or injecting apropriate cookies. - Adblock rules don’t cover everything. I had to hack
mitm-adblocka little to e.g. blockoptad360andstatsforadssites - some sites like e.g. Twitter don’t work well with the solution. This can be solved by putting
custom code in
webscreenshot.js, though
There are also some further enhancements features I see:
- scrapping page HTML, so one can do a quick
grepto find information - using tesseract or other OCR on page screenshot to extract visible text instead of pure HTML
- crop page screenshots to exclude meaningless space, to save space (my screenshot dir is about 700MB)