
savis - visualize SQLAlchemy models without fuss
Some time ago I realized that our project is a victim of NoSQL hype (hey! hype cycle). It was actually my fault when I introduced it. There was specific motivation behind that decision, but that’s something I would like to keep for separate post.
Couple of days ago I started to work on a plan to migrate to SQL. I extracted all of the keys and respective schemas from our NoSQL store and started doing ML. By ML I don’t mean Machine Learning, but Manual Labor :-).
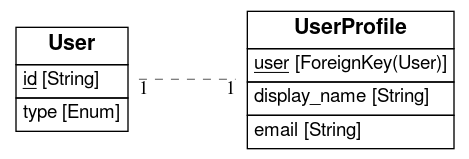
Our project grew surprisingly big in terms of number of keys and relations between them. One option to proceed would be to rewrite everything from scratch. But I didn’t want to do so. Based on my experience such big rewrites almost always backfire. I was looking how to split the keyspace so we can proceed in more iterative way. I was experimenting a lot and what I missed was an easy way to write models and see ERD (entity relationship diagram).
Ideally what I was looking for would:
- let me control the data (yes, online ERD tools, I’m looking at you)
- let me write model/entity definitions only once
- let me create ER diagram without running database
- let me test these models in action without any modifications
All online and offline tools didn’t match my requirements. The only project I’ve found was eralchemy, which is great, but you either have to run database, or write models in a custom markdown format.
Maybe there is something I couln’t find in the internet, who knows. But at that time
I decided to write small pet project that will satisfy me. It’s called savis -
SqlAlchemy VISualizer. The tool is available at GitHub. Rest of the post contains
details how it was built.
Eralchemy is definitely a great tool. It’s close to what I wanted but in order to obtain ER diagram you need to
- write your models, run migrations, extract schema
- create a copy of your models in markdown notation
We don’t want to run database, because we might want to change our models quite rapidly and see the impact immediately. This leaves us with option b only. But how do we maintain only one definition of our models? It’s simple: we write a program that reads Python source files, extracts all of the models and prints them out in target format.
Although it could be done by interpreting Python files just as they were test files, but this wouldn’t be bullet proof. But Hey! Python’s motto is “Batteries included”! It comes with a library we can use to do this the right way - ast. We’re gonna use parser to convert textual file into Abstract Syntax Tree. Then it’s all about using it to find all of the classes, filtering out those which aren’t models, extracting class members and producing final output. Let’s see how do we do all of this.
Firstly we need to look for possible files. We can use glob library to do this:
for file_ in input_dir.glob('**/*.py'):
process_file(file_)
We’re using construct called glob.
It looks like a regex, but it isn’t one. Whenever you use bash you can pass such a
glob expression - e.g. in order to recursively find files with .py extension you
can use following spell. I highly recommend to read linked documentation as even
seasoned software engineers aren’t aware of certain features. See man glob for
further details.
ls **/*.py
Neat thing, isn’t it?
Python’s glob library does the same. Speaking about paths… I recommend pathlib
library which is used to work with paths like a boss. Representing paths with strings
can be cumbersome. Maybe in our case it would be like using a cannonball against a fly,
but knowing/using more libraries won’t hurt.
Once we have a path to file that can contain model definitions we should look for
them! A model is a Python class that has extra field: __tablename__. We will make
use of this requirement.
But how do we convert a file into something we can work on? How do we use ast library?
It’s pretty simple as it turns out:
with open(file_) as f:
root = ast.parse(f.read(), file_)
ast library parses the file and returns tree root. From now on we can continue
working on that tree. We have to recursively traverse it to find classes that
are indeed SQLAlchemy models. At some point we’ll want to iterate over models
to generate their representation. for model in get_models(tree) looks like
pythonic way, so our implementation should be a generator.
All nodes in the tree that aren’t classes should be omitted. Since each node
is of specific type we can filter nodes using type call. If the node isn’t
of ast.ClassDef type we should recurse, because there still might be class
definitions deeper. Please consider following example. This is, BTW, good example
why doing a grep-like processing is bad idea.
def foo(var=None):
if var:
class Bar:
pass
return Bar()
Second ingredient is __tablename__ class member. If it’s present in the class
definition, then we’re talking about SQLAlchemy model. Here’s the code:
def find_models(node):
if isinstance(node, ast.ClassDef):
if '__tablename__' in get_member_names(node):
yield node
if hasattr(node, 'body'):
for child in node.body:
yield from find_models(child)
Some of the nodes won’t have body attribute, so we have to filter out these
too. I believe that the code is straightforward, so let’s continue with how
we can implement get_member_names. This function will extract names of
all class members.
def get_member_names(node):
if not hasattr(node, 'body'):
return
for member in node.body:
if not hasattr(member, 'targets') or not member.targets:
continue
for target in member.targets:
yield target.id
Again, we’re checking if this is bodyful node. Then we’re iterating over
all childs of that particular node. We’re looking for ast.Assign members
(e.g. variable = value) but there’s no need to use type - we can directly
check if there is target attribute. Nodes having it are representing
assignments. Target is, simply speaking, a variable to which value will be
written to. We iterate over targets (Python support constructs like
a, b = a, b where there are more targets than one) and yield them. Voille-a!
Frankly speaking we’re almost done. We need to extract types of the class
members, check out which parameters are passed to them etc. All fields that
represent columns in SQL will be a sqlalchemy.Column instances. primary_key
is a keyword used to denote a primary key etc. We just need to take all of
this into account. Full code is available here.
What it gives us finally? A markdown file that eralchemy can understand and display. It’s not complicated. It’s not complete either. But it works :-).